Кластеризация экземпляров процесса с помощью Python-блоков
В этом документе показано, как построить собственный сценарий кластеризации экземпляров процесса в Proceset с помощью Python-блоков, вывести результат на дашборд и использовать его для анализа отклонений на Карте процесса и в Сфере процессов.
Контекст
Компания анализирует процесс согласования закупок. В рамках этого процесса заявки могут проходить по нескольким сценариям:
- Часть заявок проходит по базовому маршруту без возвратов
- Часть заявок возвращается на доработку
- Часть заявок уходит на дополнительное согласование
- Часть заявок связана с повышенной стоимостью и требует отдельного контроля
Ручной анализ каждого экземпляра занимает слишком много времени. Нужен сценарий, который:
- Автоматически собирает признаки по экземплярам процесса.
- Распределяет экземпляры по кластерам с помощью Python-блока.
- Показывает результат на дашборде.
- Позволяет открыть Карту процесса уже с фильтром по выбранному кластеру.
- Помогает определить, какой сценарий нужно оптимизировать в первую очередь.
Настройка кластеризации экземпляров процесса и анализа результата на дашборде
Настройка кластеризации экземпляров процесса и анализа результата на дашборде выполняется в шесть этапов:
- Этап 1 — создание таблиц, настройка модели данных и подготовка структуры для хранения результатов кластеризации
- Этап 2 — добавление пользовательского Python-блока, который выполняет кластеризацию экземпляров процесса
- Этап 3 — создание и публикация скрипта, который собирает признаки по экземплярам процесса, запускает Python-блок и записывает результат в таблицу
- Этап 4 — построение дашборда с KPI, диаграммами, таблицей характеристик кластеров
- Этап 5 — создание процесса в модели данных и подготовка его для отображения в Карте процесса и Сфере процессов
- Этап 6 — интерпретация кластеров, фильтрация процесса по выбранному кластеру и применение результата в работе аналитика
Также вы можете ознакомиться с примером рабочего процесса, демонстрирующим, как аналитик находит кластер с возвратами на доработку, открывает его на Карте процесса и определяет участок процесса, который требует оптимизации.
Подготовка таблиц и модели данных
Для реализации нужны две таблицы:
process_event_log— журнал событий процессаcluster_case_clusters— таблица результатов кластеризации
Таблица «process_event_log»
Таблицу можно загрузить заранее для реализации примера, описанного в документе, либо собрать данные отдельно любым удобным для вас способом, например:
- Собрать данные скриптом автоматизации из внешней системы и записать в таблицу
- Использовать JS-трекер, если источник — сайт или веб-приложение
- Подключить уже существующую таблицу из ClickHouse
Таблица должна содержать историю событий по экземплярам процесса. В ней должны быть следующие обязательные поля:
case_id— идентификатор экземпляра процесса. Используется для объединения всех событий, относящихся к одному кейсу, и для связи журнала событий с таблицей кейсов и таблицей результатов кластеризации. Значение должно быть уникальным в рамках одного экземпляра процесса, но может повторяться в нескольких строках таблицы, так как один кейс обычно содержит несколько событийevent_name— название события процесса. Описывает, какое действие или этап был выполнен в рамках кейса, напримерCreate request,Check documents,Approve,Return for rework,Complete. На основе последовательности значений этого поля формируется маршрут экземпляра процесса, который затем используется в кластеризации как один из признаковevent_ts— дата и время наступления события. Используется для упорядочивания событий внутри кейса в правильной хронологической последовательности. Также на основе этого поля можно рассчитать длительность прохождения кейса, время между этапами и другие временные характеристики процессаcost— стоимость, связанная с кейсом или событием. Используется как числовой признак для кластеризации и как аналитический показатель на дашборде. В зависимости от модели данных это может быть стоимость всей заявки, сумма по позиции, стоимость на момент события или другое числовое значение, которое помогает отличать дорогие сценарии от типовыхdepartment— подразделение, отдел или другая организационная единица, связанная с кейсом. Поле позволяет анализировать, в каких подразделениях чаще возникают определенные сценарии процесса, например возвраты на доработку, длительное согласование или дорогие кейсы. Может использоваться для фильтрации и сегментации на дашбордеchannel— канал поступления или создания кейса. Показывает, откуда пришел экземпляр процесса, напримерEmail,Portal,Manual,API. Поле используется для анализа того, влияет ли источник поступления заявки на маршрут процесса, длительность, количество возвратов или вероятность попадания в проблемный кластер
Если вам нужно использовать дополнительные признаки в кластеризации, также подготовьте поля стоимости, подразделения, канала поступления или других атрибутов, которые помогают отличать сценарии исполнения.
Чтобы загрузить таблицу в модель данных:
- Нажмите + Добавить таблицу → Импортировать.
- Выберите нужный разделитель Точка с запятой (;), квалификатор Двойные кавычки (") и кодировку UTF-8 и кликните Нажмите или перетащите файл сюда.
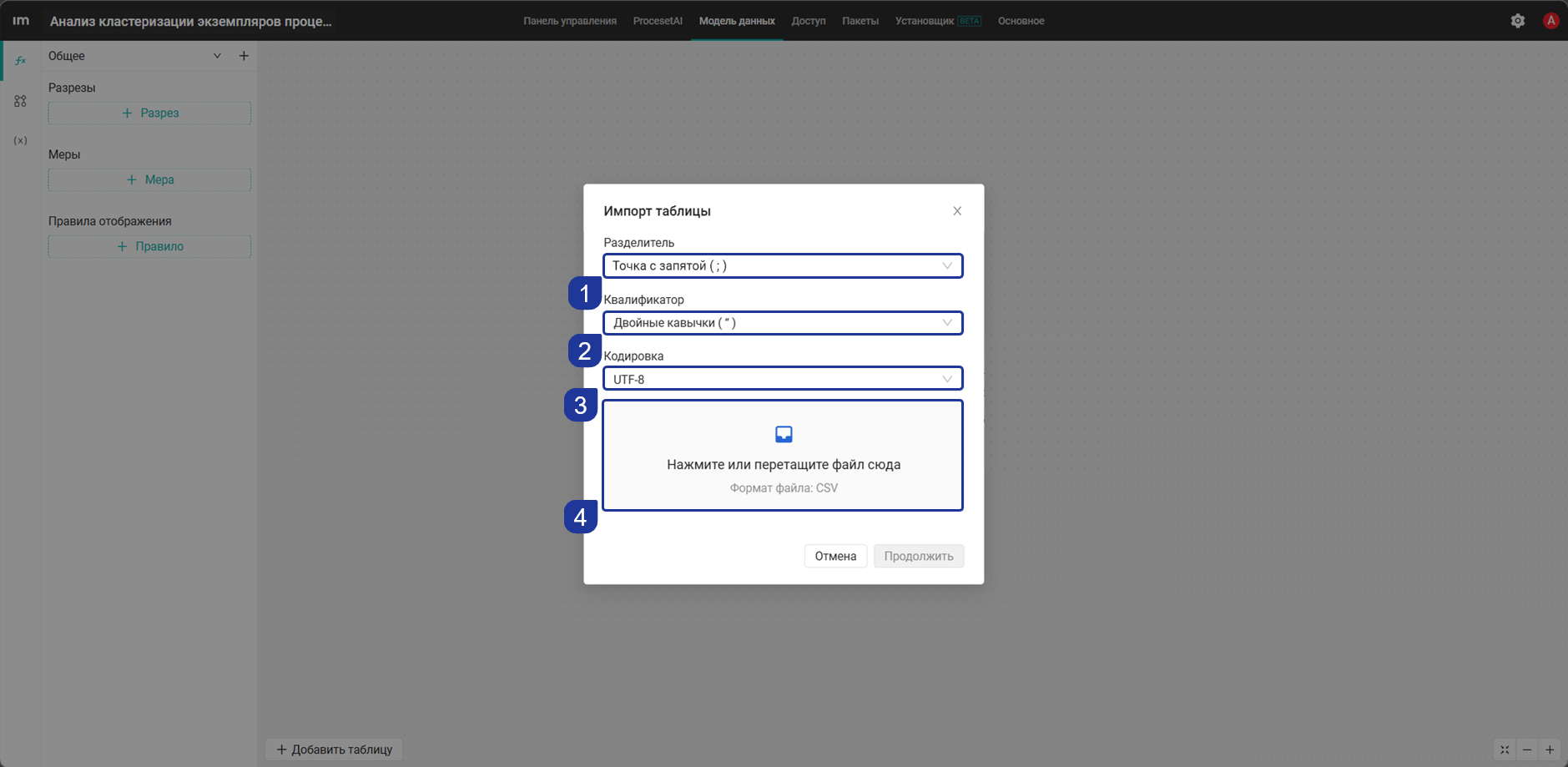
- Выберите скачанную таблицу в формате
.csvи нажмите Продолжить.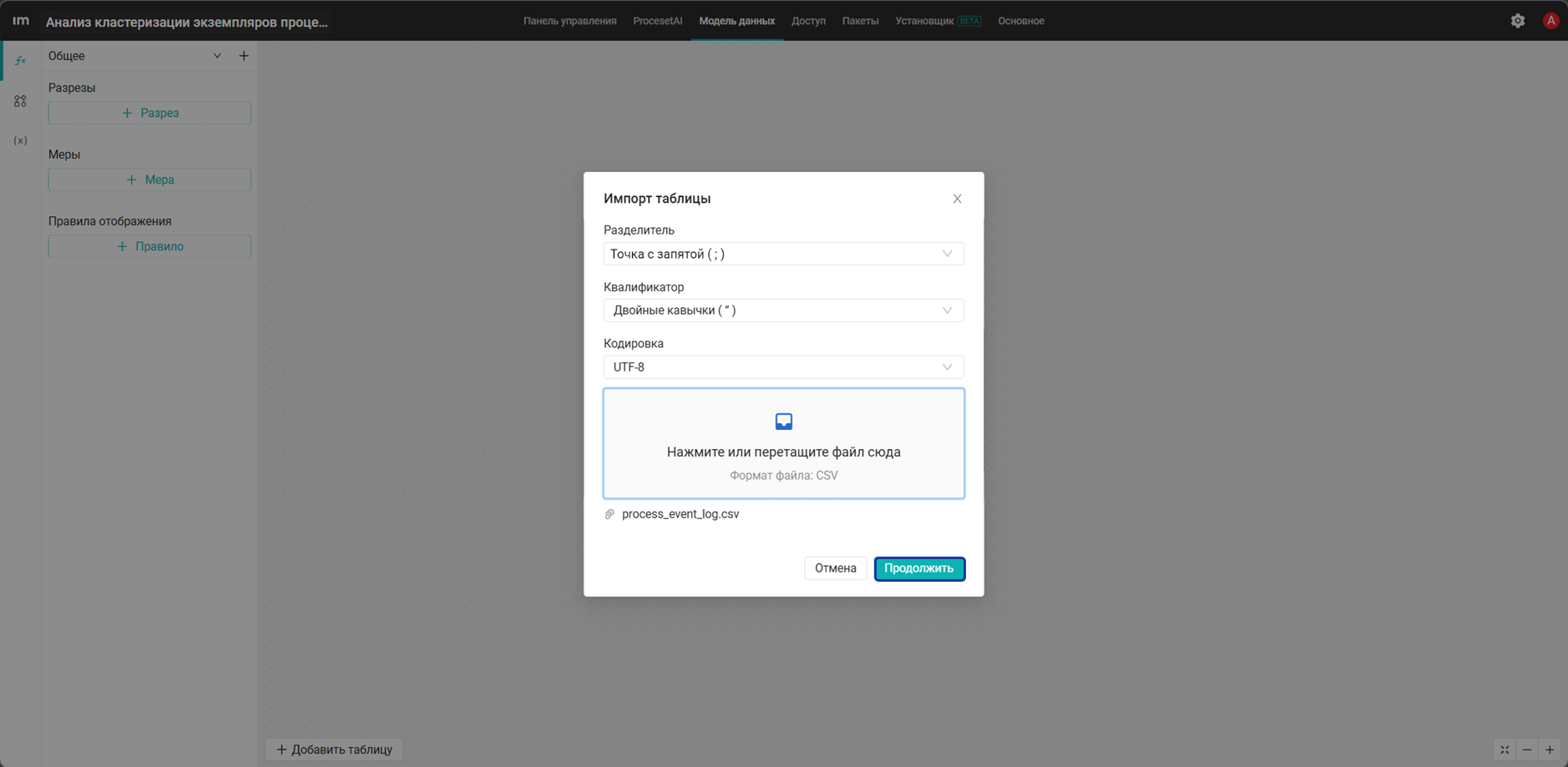
- В открывшемся окне нажмите Импортировать.
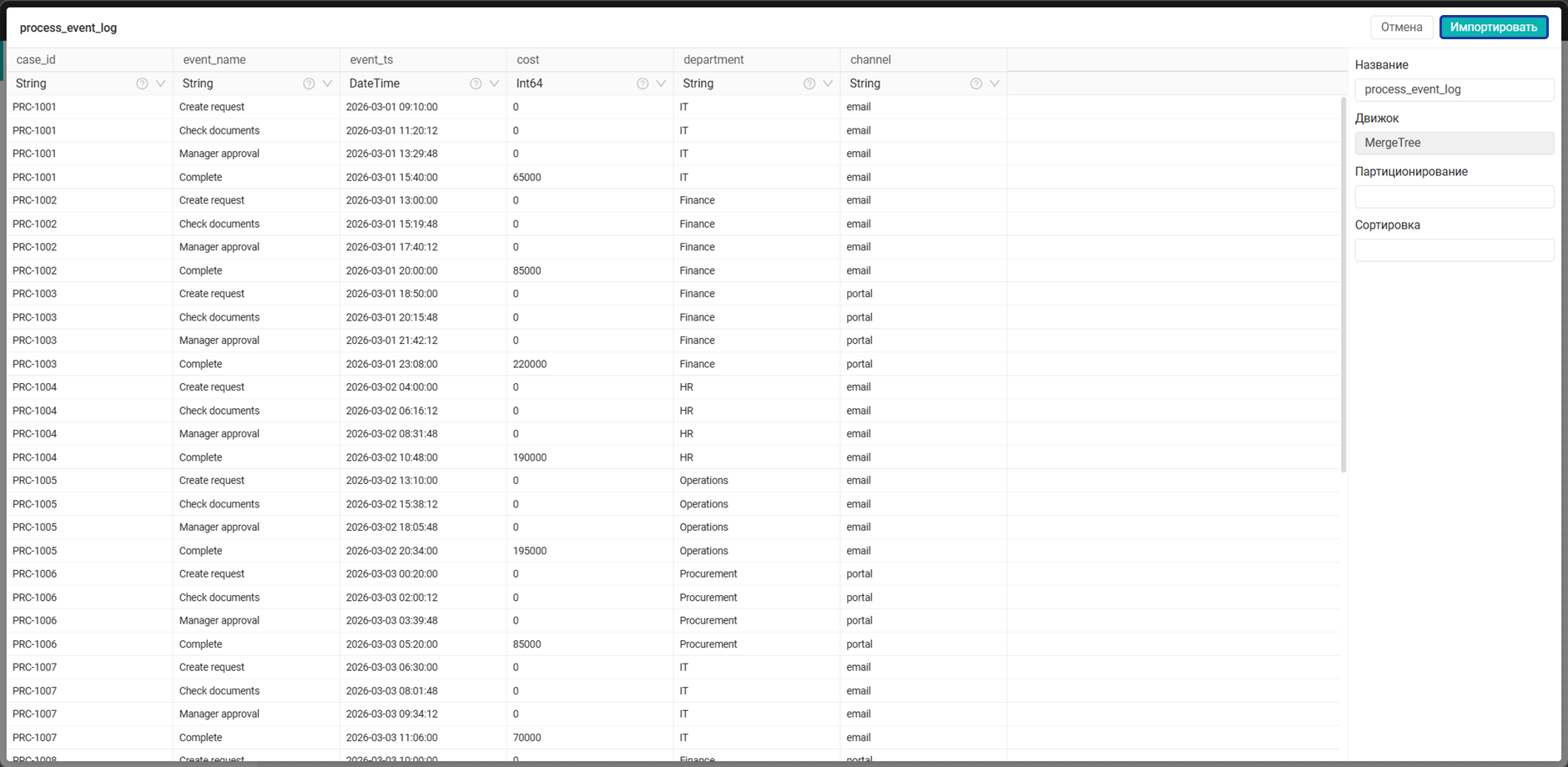
Таблица «cluster_case_clusters»
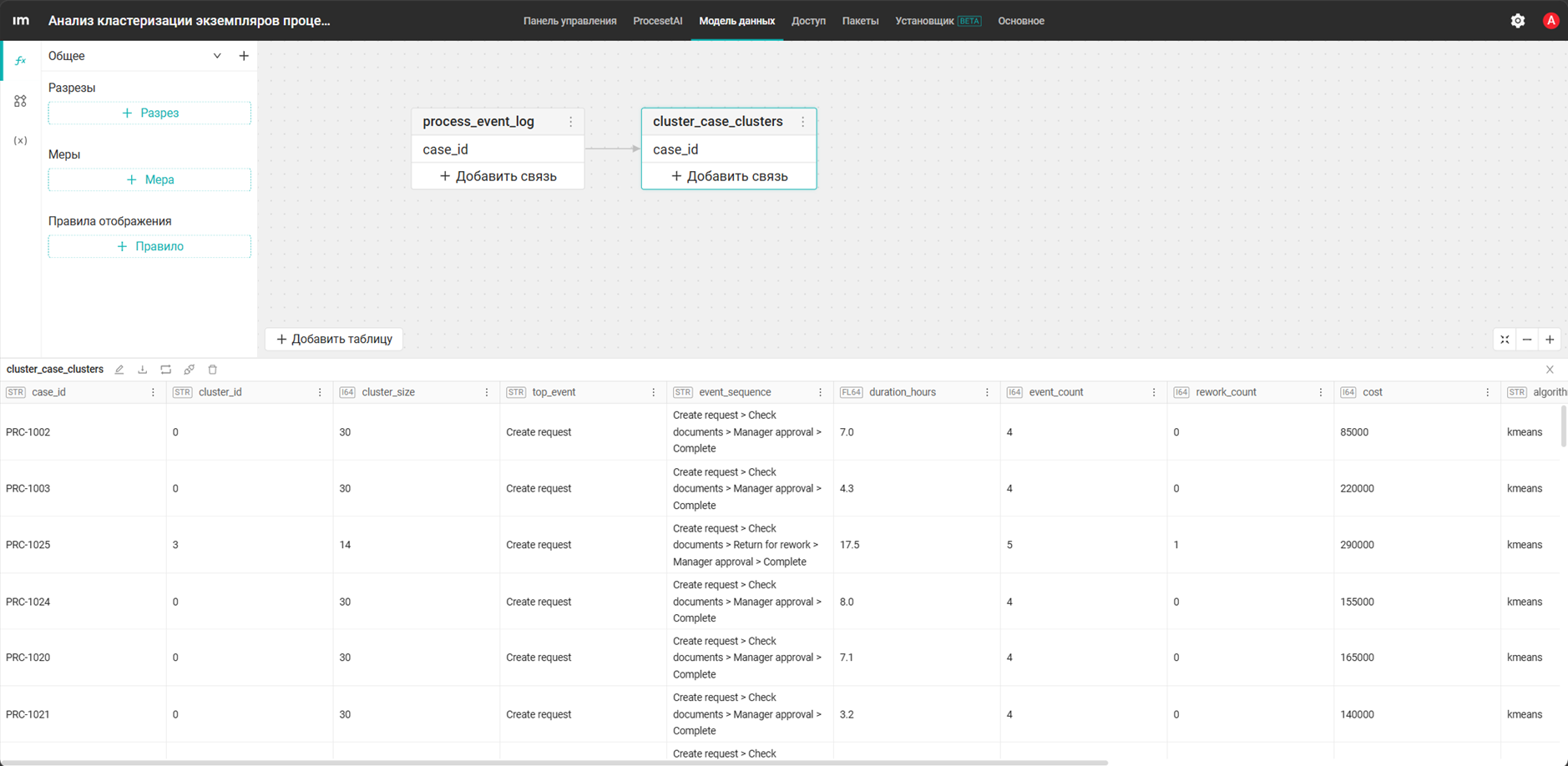
Создайте пустую таблицу в модели данных cluster_case_clusters со следующими колонками:
Колонка cluster_id хранится как строка, чтобы для алгоритма OPTICS можно было сохранить специальное значение noise для шума.
case_id— идентификатор экземпляра процесса. Соответствует полюcase_idв журнале событий и таблице кейсов. Используется для связи результата кластеризации с исходными данными процесса, чтобы можно было фильтровать процессные и аналитические виджеты по выбранному кластеруcluster_id— идентификатор кластера, к которому отнесен экземпляр процесса. Хранится как строка, чтобы поддерживать не только числовые идентификаторы кластеров, но и специальные значения, например noise для шума в алгоритме OPTICS. Это основное поле для группировки, фильтрации и сравнения сценариев на дашбордеcluster_size— размер кластера, то есть количество экземпляров процесса, попавших в этот кластер. Позволяет определить, насколько типовым или редким является сценарий. Используется для сравнения кластеров по объему и для поиска крупных или, наоборот, аномально малых групп экземпляров процессаtop_event— наиболее характерное событие внутри кластера. Рассчитывается как самое частотное событие среди экземпляров процесса данного кластера. Помогает быстро понять общий характер сценария, например связан ли кластер с возвратами, согласованием или завершениемevent_sequence— последовательность событий конкретного экземпляра процесса в текстовом виде. Представляет маршрут экземпляра процесса как упорядоченный список событий, напримерCreate request > Check documents > Approve > Complete. Используется как один из основных признаков при кластеризации экземпляров процесса, так как именно маршрут процесса чаще всего определяет различие между сценариямиduration_hours— общая длительность экземпляра процесса в часах. Рассчитывается как разница между первым и последним событием экземпляра процесса. Используется как числовой признак при кластеризации и как показатель для анализа затянутых сценариев на дашбордеevent_count— общее количество событий в экземпляре процесса. Показывает сложность маршрута: число шагов, повторяющиеся действия, дополнительные ветки согласованияrework_count— количество возвратов, повторных проверок или иных событий доработки в экземпляре процесса. Используется как отдельный признак проблемности процесса. Поле особенно полезно для поиска кластеров, связанных с возвратами на доработку, повторным согласованием или циклическим прохождением одних и тех же этаповcost— стоимость экземпляра процесса, используемая в результате кластеризации. Обычно содержит суммарное значение стоимости по экземпляру процесса. Поле помогает выявлять отдельные сценарии для дорогих кейсов и сравнивать кластеры не только по маршруту и длительности, но и по финансовой нагрузкеalgorithm— название алгоритма кластеризации, использованного для расчета. Например,kmeansилиoptics. Поле хранит информацию о способе получения текущего набора кластеров и используется для сравнения результатов разных запусковsilhouette_score— значение коэффициента силуэта для текущего запуска кластеризации. Используется как метрика качества разбиения на кластеры. Чем выше значение, тем лучше объекты внутри одного кластера похожи друг на друга и отличаются от объектов других кластеров. Обычно это служебный показатель уровня запуска, но он записывается в каждую строку результата для удобства отображения на дашбордеdavies_bouldin_score— значение коэффициента Дэвиса–Болдина для текущего запуска кластеризации. Это еще одна метрика качества кластерной структуры. В отличие от коэффициента силуэта, для нее меньшие значения обычно означают более качественное разделение кластеров. Также относится к показателям уровня запускаrun_ts— дата и время выполнения расчета кластеризации. Показывает, когда именно был получен данный результат. Поле помогает отличать результаты разных запусков, контролировать актуальность данных и при необходимости анализировать изменения кластеров во времени
Для создания таблицы в модели данных:
- Нажмите + Добавить таблицу → Создать.
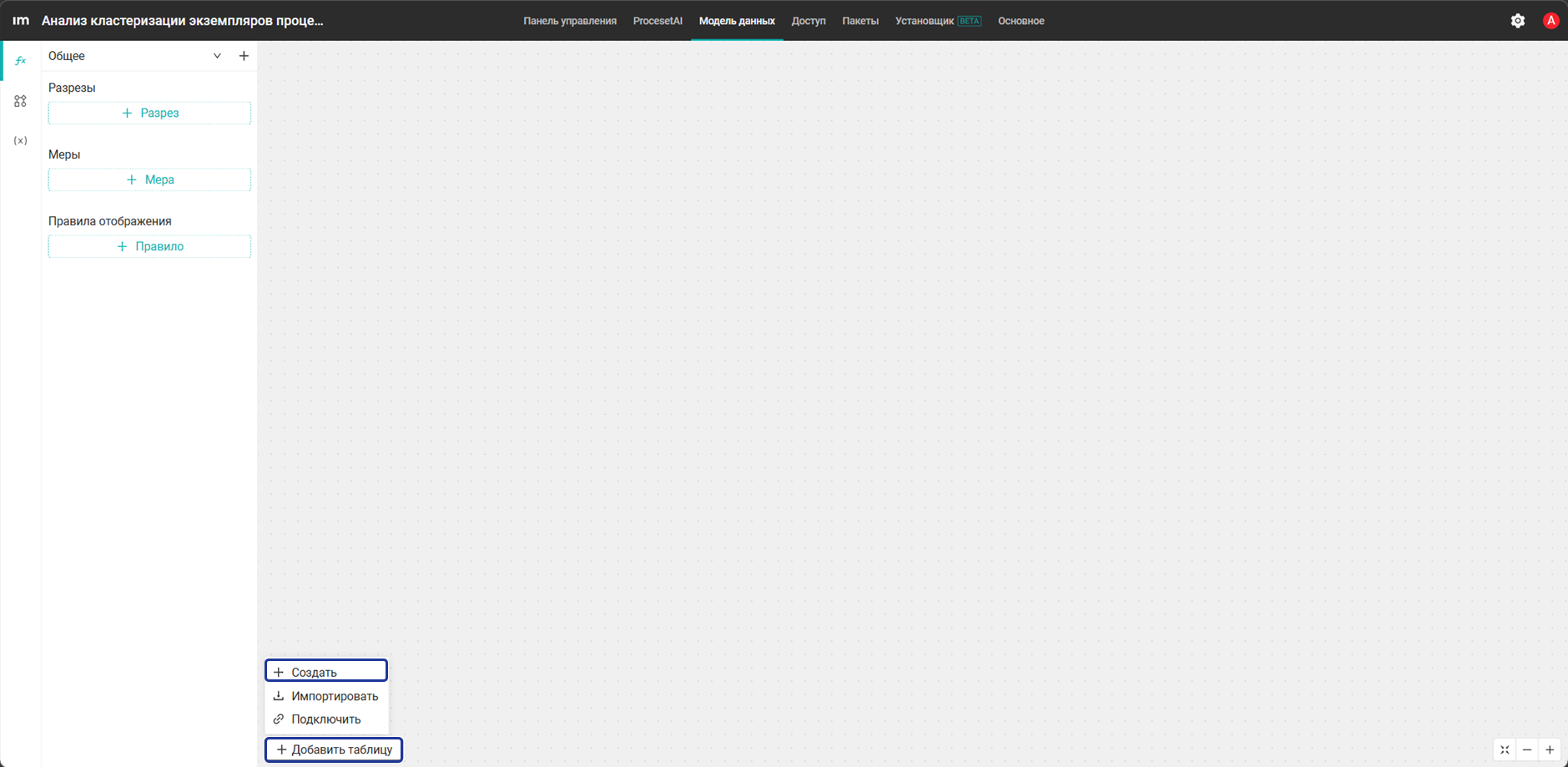
- Затем заполните колонки таблицы, как показано на скриншоте ниже, и нажмите Добавить.
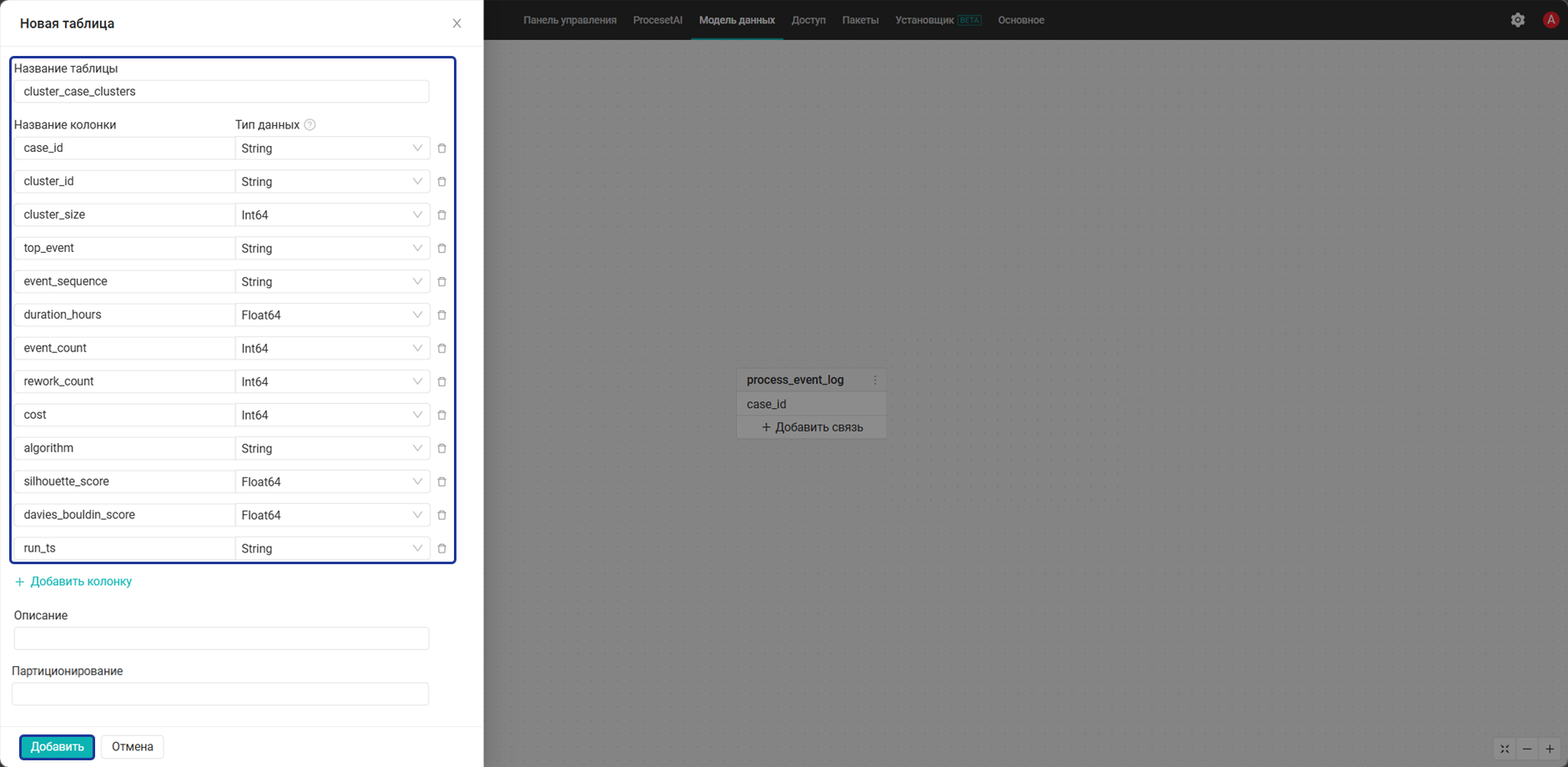
После создания таблицы свяжите ее в модели данных с таблицей журнала событий по полю case_id. Эта связь нужна, чтобы процессные виджеты могли принимать фильтр по кластеру через связанную таблицу:
- Нажмите + Добавить связь на таблице
process_event_logи выберите таблицуcluster_case_clustersдля создания связи. - Свяжите таблицы по полю
case_idи укажите тип связи Многие к одной, после нажмите Сохранить.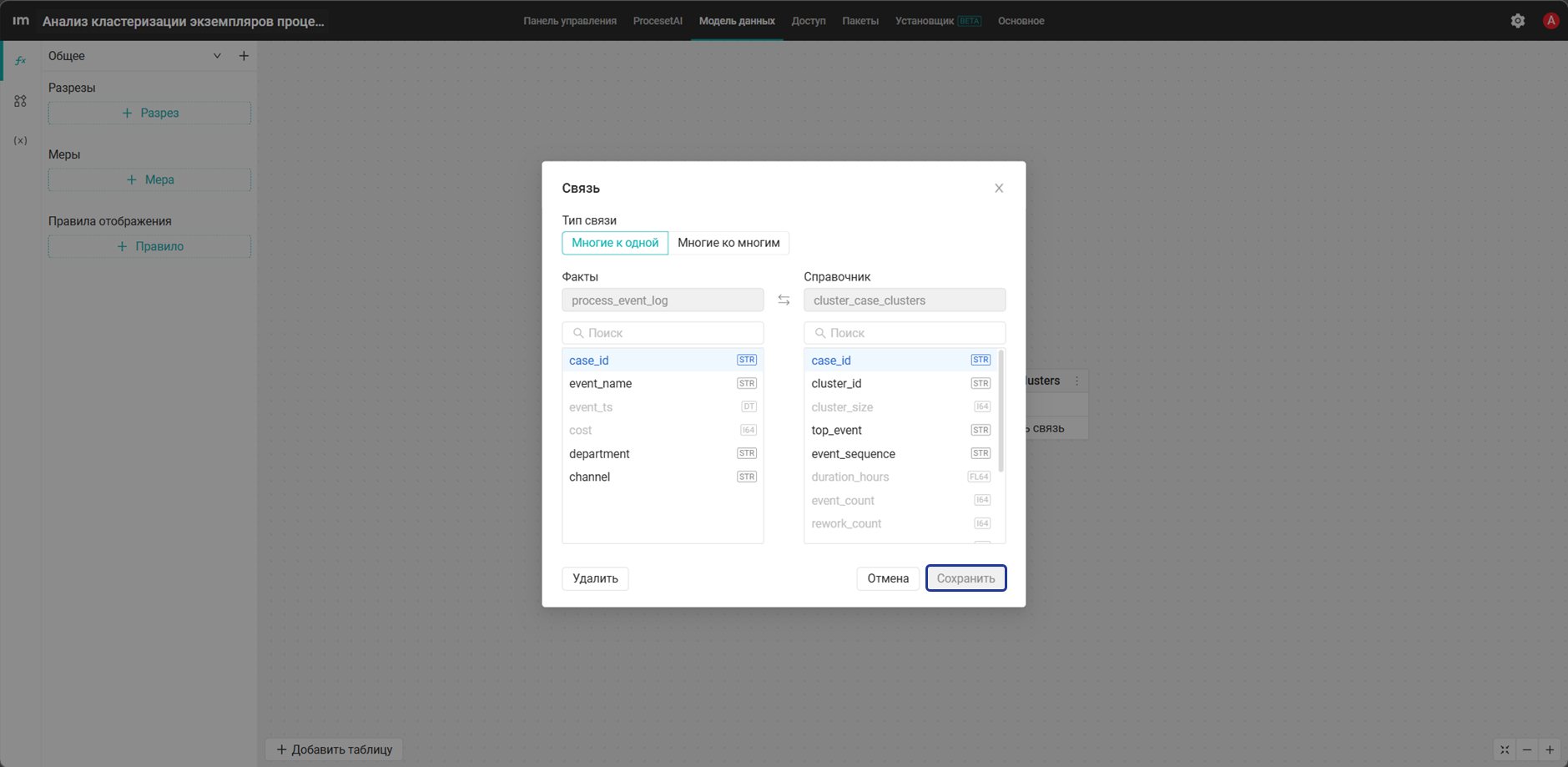
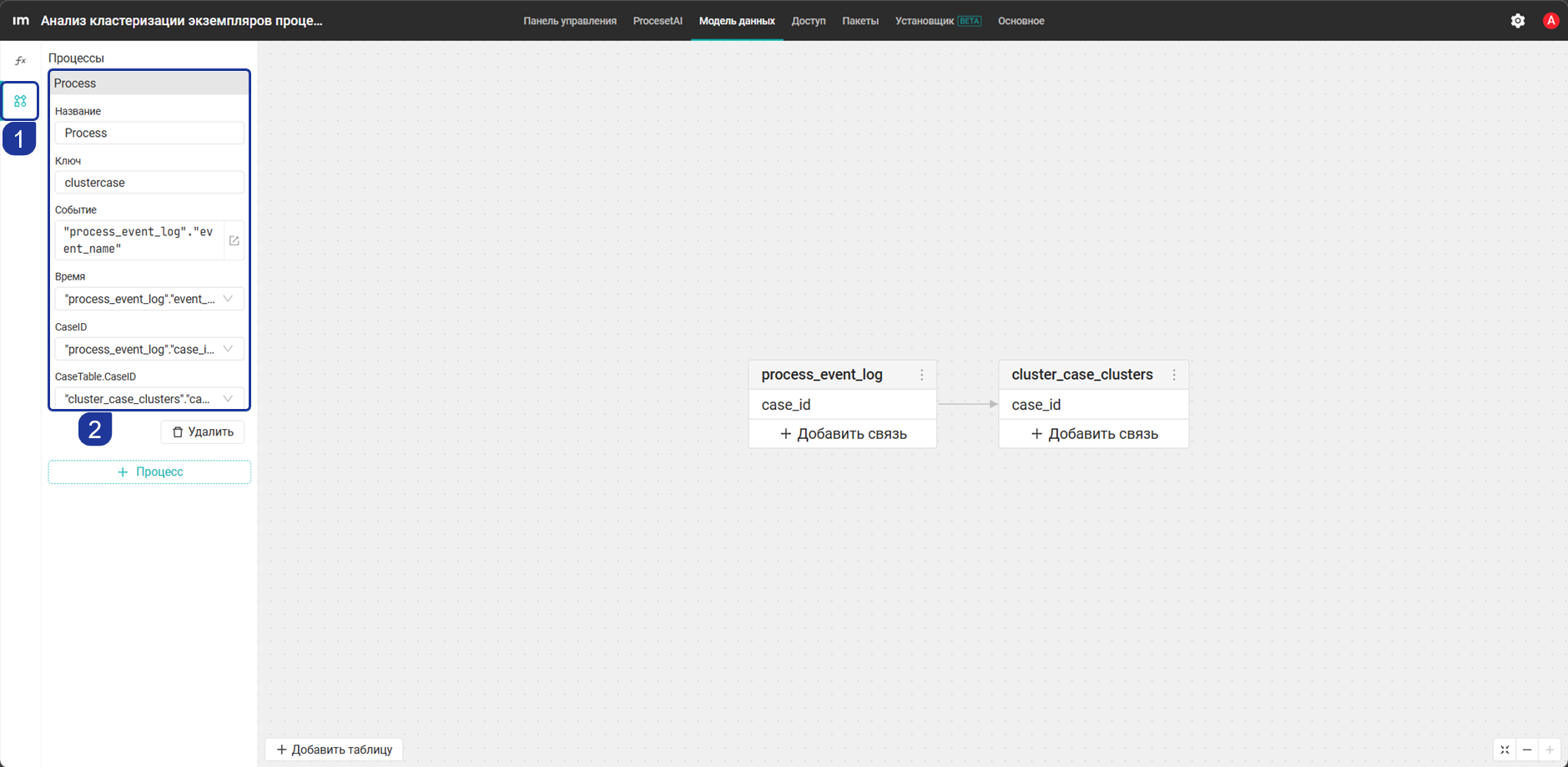
Настройка процесса в модели данных
Нужно настроить процесс в модели данных.
- Перейдите во вкладку Процессы, нажмите + Процесс и заполните все поля, как показано на скриншоте ниже.
Подготовка пакета Python-блоков
Для реализации кластеризации в рамках кейса создается Python-блок с использованием Python SDK.
Блок будет частью пакета — структурированного набора файлов, который описывает логику работы блока, его параметры и зависимости. Пакет формируется вручную — вы создаете файлы с кодом, настраиваете зависимости и размещаете их в нужной директории на сервере.
Ниже приведена структура пакета:
/usr/sbin/infomaximum/python/
├── entrypoint.py
├── requirements.txt
└── packages/
└── process_clustering/
├── __init__.py
├── group.py
└── blocks/
├── __init__.py
└── cluster_instances_block.py
entrypoint.py и конфигурацию контейнера оставьте стандартными для вашего шаблона Python SDK.
Настройка requirements.txt
Файл requirements.txt должен находиться в корне пакета (/usr/sbin/infomaximum/python/). Если файла нет, создайте его. В файл добавьте библиотеки, необходимые для работы Python-блока. Если в файле уже есть другие зависимости, просто допишите строки ниже в конец файла:
pandas==2.2.3
numpy==2.1.3
scikit-learn==1.5.2
gensim==4.3.3
scipy==1.14.1
Добавление группы «Кластеризация»
Группа — это логическое объединение блоков в интерфейсе конструктора скриптов. Чтобы создать группу Кластеризация:
- В структуре пакета откройте или создайте файл
packages/process_clustering/group.py. - Добавьте в него код, представленный ниже.
from sdk.abstract_group import AbstractGroup import os class ProcessClusteringGroup(AbstractGroup): def __init__(self): super().__init__() def get_uuid(self): return "process_clustering_group_7d5d1e43-b1e0-4fb5-9c4b-9f8a1a41b501" def get_name(self): return { "en": "Clustering", "ru": "Кластеризация", } def get_category(self): return "tools" def get_icon(self): return os.path.join( os.path.dirname(os.path.realpath(__file__)), "process_clustering_group.png" ) - Сохраните файл. После формирования пакета группа появится в интерфейсе конструктора скриптов в категории Инструменты.
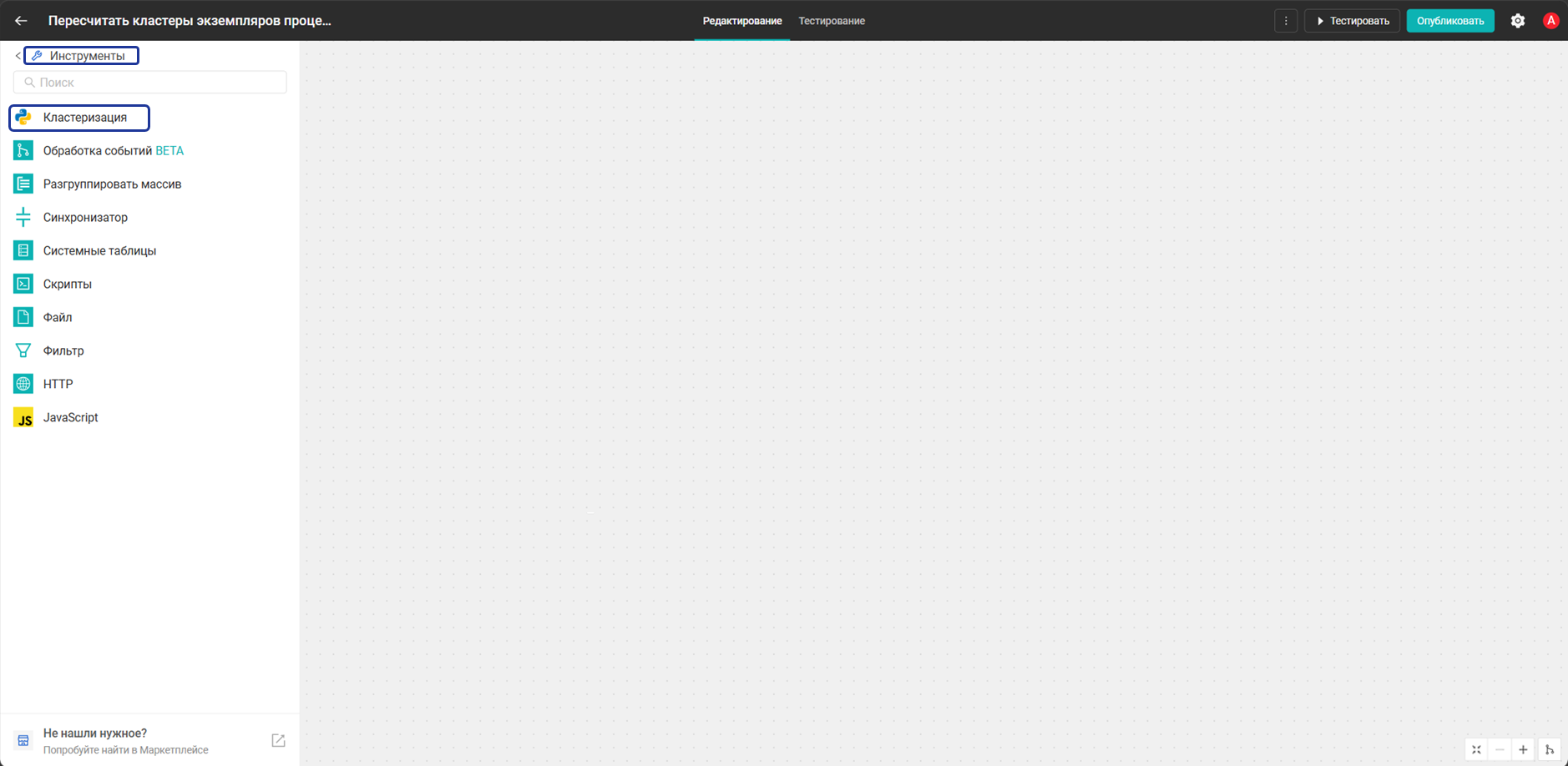
Добавление блока «Кластеризация экземпляров процесса»
Блок — это исполняемый компонент, который принимает входные данные, выполняет логику и возвращает результат. Чтобы добавить блок Кластеризация экземпляров процесса в созданную выше группу:
- В структуре пакета откройте или создайте файл
packages/process_clustering/blocks/cluster_instances_block.py. - Добавьте в него код, представленный ниже.
В текущей реализации блок:
- Принимает
case_id, последовательность событий и числовые признаки - Поддерживает алгоритмы
kmeansиoptics - Рассчитывает служебные метрики качества кластеризации
from sdk.abstract_block import AbstractBlock from collections import Counter from datetime import datetime import numpy as np import pandas as pd from scipy.sparse import csr_matrix, hstack from sklearn.cluster import KMeans, OPTICS from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics import davies_bouldin_score, silhouette_score from sklearn.preprocessing import StandardScaler class ClusterProcessInstancesBlock(AbstractBlock): """ Агрегационный блок. Принимает набор экземпляров процесса, выполняет кластеризацию и возвращает одну строку результата на каждый экземпляр процесса. """ def __init__(self): super().__init__() def get_uuid(self): return "cluster_process_instances_block_3623f5c4-b8b4-48cc-8a4f-0d0cc4fa7a11" def get_type(self): return "action" def get_name(self): return { "en": "Clustering process instances", "ru": "Кластеризация экземпляров процесса", } def get_description(self): return { "en": "Clusters process instances by event sequence and numeric features", "ru": "Кластеризует экземпляры процесса по последовательности событий и числовым признакам", } def get_compatible_connections(self): return [] def get_optionals(self): return { "is_save_data_on_fail_block_type": False, "is_system_block_type": False, } def get_fields(self): return """[ { key: 'case_id', type: 'text', label: 'ID экземпляра', required: true }, { key: 'event_sequence', type: 'text', label: 'Последовательность событий', hint: 'Например: Создание > Проверка > Согласование > Завершение', required: true, enableFullscreen: true }, { key: 'duration_hours', type: 'number', label: 'Длительность, часы', required: true }, { key: 'event_count', type: 'number', label: 'Количество событий', required: true }, { key: 'rework_count', type: 'number', label: 'Количество возвратов', required: false }, { key: 'cost', type: 'number', label: 'Стоимость', required: false }, { key: 'algorithm', type: 'text', label: 'Алгоритм', hint: 'kmeans или optics', required: true, default: 'kmeans' }, { key: 'n_clusters', type: 'text', label: 'Количество кластеров', hint: 'Используется для kmeans', required: false, default: '4' }, { key: 'min_samples', type: 'text', label: 'min_samples', hint: 'Используется для optics', required: false, default: '5' }, { key: 'random_state', type: 'text', label: 'Начальное состояние генератора', required: false, default: '42' }, { key: 'scale_numeric', type: 'boolean', label: 'Масштабировать числовые признаки', default: true }, { key: 'separator', type: 'text', label: 'Разделитель событий', required: true, default: ' > ' } ]""" def get_block_input(self): return { "case_id": "String", "event_sequence": "String", "duration_hours": "Double", "event_count": "Long", "rework_count": "Long", "cost": "Long", "algorithm": "String", "n_clusters": "String", "min_samples": "String", "random_state": "String", "scale_numeric": "Boolean", "separator": "String", } def get_block_output_options(self): return { "default": [ {"name": "case_id", "type": "String"}, {"name": "cluster_id", "type": "String"}, {"name": "cluster_size", "type": "Long"}, {"name": "top_event", "type": "String"}, {"name": "event_sequence", "type": "String"}, {"name": "duration_hours", "type": "Double"}, {"name": "event_count", "type": "Long"}, {"name": "rework_count", "type": "Long"}, {"name": "cost", "type": "Long"}, {"name": "algorithm", "type": "String"}, {"name": "silhouette_score", "type": "Double"}, {"name": "davies_bouldin_score", "type": "Double"}, {"name": "run_ts", "type": "String"} ] } def get_block_output(self, data_sample: dict): return self.get_block_output_options()["default"] def get_block_aggr_mode(self, data_sample: dict) -> bool: return True def get_batch_size(self): return 5000 @staticmethod def _safe_float(value, default=0.0): if value is None or value == "": return float(default) return float(value) @staticmethod def _safe_int(value, default=0): if value is None or value == "": return int(default) return int(float(value)) @staticmethod def _safe_str(value, default=""): if value is None: return default return str(value) @staticmethod def _split_sequence(sequence, separator): if sequence is None: return [] return [token.strip() for token in str(sequence).split(separator) if token.strip()] def process_data(self, **data): block_data = data["block_data"] df = pd.DataFrame(block_data).copy() if df.empty: return [] """ Нормализация входных данных """ df["case_id"] = df["case_id"].apply(lambda x: self._safe_str(x)) df["event_sequence"] = df["event_sequence"].apply(lambda x: self._safe_str(x)) df["duration_hours"] = df["duration_hours"].apply(lambda x: self._safe_float(x, 0.0)) df["event_count"] = df["event_count"].apply(lambda x: self._safe_int(x, 0)) df["rework_count"] = df["rework_count"].apply(lambda x: self._safe_int(x, 0)) df["cost"] = df["cost"].apply(lambda x: self._safe_int(x, 0)) first_row = df.iloc[0].to_dict() algorithm = self._safe_str(first_row.get("algorithm"), "kmeans").strip().lower() if algorithm not in ("kmeans", "optics"): algorithm = "kmeans" n_clusters = max(2, self._safe_int(first_row.get("n_clusters"), 4)) min_samples = max(2, self._safe_int(first_row.get("min_samples"), 5)) random_state = self._safe_int(first_row.get("random_state"), 42) scale_numeric = first_row.get("scale_numeric", True) if isinstance(scale_numeric, str): scale_numeric = scale_numeric.strip().lower() in ("true", "1", "yes") else: scale_numeric = bool(scale_numeric) separator = self._safe_str(first_row.get("separator"), " > ") if len(df) < 2: run_ts = datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S") result = [] for _, row in df.iterrows(): result.append([ str(row["case_id"]), "0", 1, "", str(row["event_sequence"]), float(row["duration_hours"]), int(row["event_count"]), int(row["rework_count"]), int(row["cost"]), algorithm, -1.0, -1.0, run_ts, ]) return result tokenized_sequences = [ self._split_sequence(value, separator) for value in df["event_sequence"].tolist() ] joined_sequences = [ " ".join(tokens) if tokens else "" for tokens in tokenized_sequences ] if not any(joined_sequences): joined_sequences = ["empty_sequence"] * len(joined_sequences) vectorizer = TfidfVectorizer( lowercase=False, token_pattern=r"[^ ]+" ) text_matrix = vectorizer.fit_transform(joined_sequences) numeric_matrix = df[[ "duration_hours", "event_count", "rework_count", "cost", ]].to_numpy(dtype=float) if scale_numeric: scaler = StandardScaler() numeric_matrix = scaler.fit_transform(numeric_matrix) numeric_sparse = csr_matrix(numeric_matrix) feature_matrix = hstack([text_matrix, numeric_sparse]).tocsr() """ Кластеризация """ if algorithm == "optics": model = OPTICS(min_samples=min_samples) labels = model.fit_predict(feature_matrix.toarray()) else: model = KMeans( n_clusters=min(n_clusters, len(df)), random_state=random_state, n_init=10, ) labels = model.fit_predict(feature_matrix) df["cluster_label"] = labels """ Расчет метрик """ silhouette = -1.0 davies = -1.0 valid_mask = (df["cluster_label"] != -1).to_numpy() valid_labels = df.loc[valid_mask, "cluster_label"].to_numpy() n_samples = int(valid_mask.sum()) n_labels = len(np.unique(valid_labels)) if n_samples > 0 else 0 if 2 <= n_labels <= n_samples - 1: valid_features = feature_matrix[valid_mask].toarray() silhouette = float(silhouette_score(valid_features, valid_labels)) davies = float(davies_bouldin_score(valid_features, valid_labels)) cluster_sizes = Counter(df["cluster_label"].tolist()) top_events = {} for label in cluster_sizes.keys(): cluster_tokens = [] for tokens, token_label in zip(tokenized_sequences, df["cluster_label"].tolist()): if token_label == label: cluster_tokens.extend(tokens) if cluster_tokens: top_events[label] = Counter(cluster_tokens).most_common(1)[0][0] else: top_events[label] = "" run_ts = datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S") result = [] for _, row in df.iterrows(): raw_label = int(row["cluster_label"]) cluster_id = "noise" if raw_label == -1 else str(raw_label) result.append([ str(row["case_id"]), cluster_id, int(cluster_sizes[row["cluster_label"]]), str(top_events[row["cluster_label"]]), str(row["event_sequence"]), float(row["duration_hours"]), int(row["event_count"]), int(row["rework_count"]), int(row["cost"]), algorithm, float(round(silhouette, 6)), float(round(davies, 6)), run_ts, ]) return result - Принимает
- Сохраните файл. После формирования пакета блок станет доступен в конструкторе скриптов в группе Кластеризация.
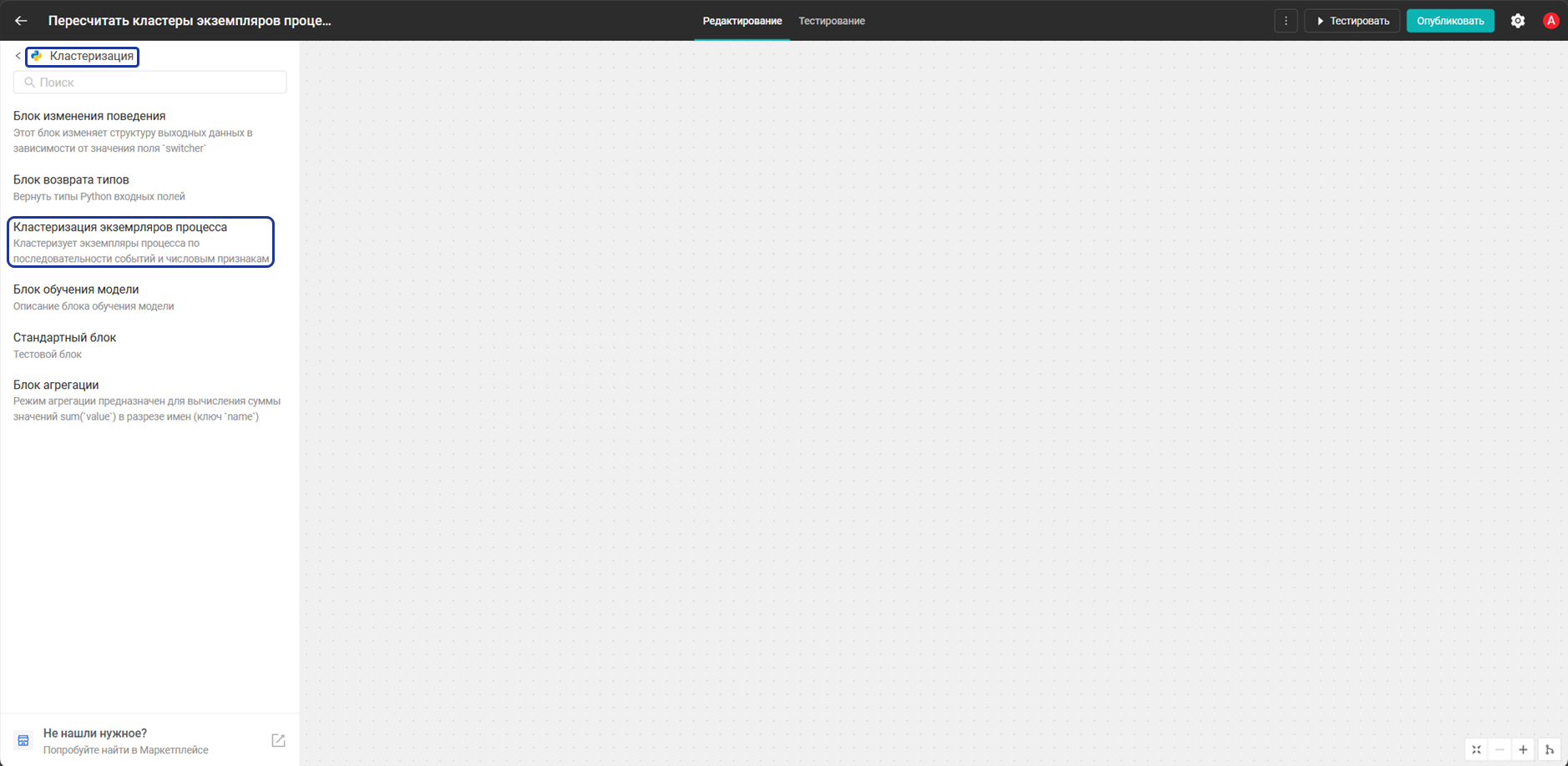
Создание скрипта кластеризации
Создайте скрипт Пересчитать кластеры экземпляров процесса. Для этого:
- В пространстве нажмите + Добавить → Скрипт.
- В открывшемся окне введите название скрипта Пересчитать кластеры экземпляров процесса и нажмите Добавить.
- Добавьте блок Планировщик и настройте расписание выполнения скрипта, например, каждые 15 минут. Протестируйте блок.
- Добавьте блок Очистить таблицу и укажите в нем таблицу
cluster_case_clusters. Протестируйте блок.
- Затем добавьте блок Выбрать строки через SQL-запрос и добавьте SQL-запрос, представленный ниже. Протестируйте блок.
В этом запросе:
SELECT toString(case_id) AS case_id, toString( arrayStringConcat( arrayMap(x -> x.2, arraySort(x -> x.1, groupArray((event_ts, event_name)))), ' > ' ) ) AS event_sequence, toFloat64(dateDiff('minute', min(event_ts), max(event_ts)) / 60.0) AS duration_hours, toInt64(count()) AS event_count, toInt64(countIf(event_name IN ('Return for rework', 'Repeated approval'))) AS rework_count, toInt64(sum(cost)) AS cost FROM process_event_log GROUP BY case_idevent_sequenceиспользуется для векторизации последовательности событий экземпляра процессаduration_hours,event_count,rework_countиcostиспользуются как числовые признаки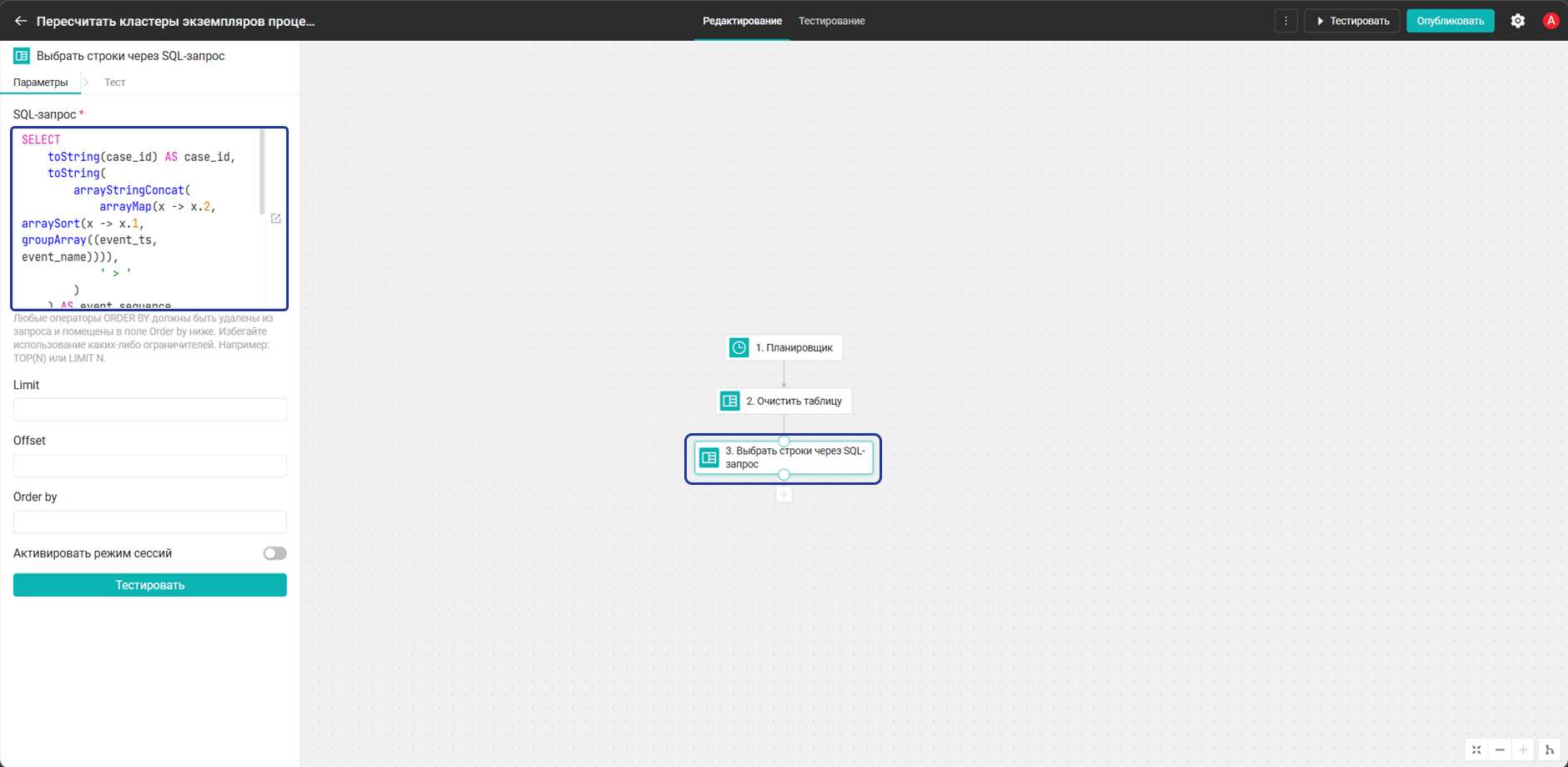
- Добавьте два одинаковых Python-блока «Кластеризация экземпляров процесса» — они должны быть подключены к блоку Выбрать строки через SQL-запрос параллельно. Заполните поля каждого из них следующим образом:
Протестируйте каждый блок отдельно.
Поле Значение для первого блока Значение для второго блока case_idcase_id(из предыдущего блока)case_id(из предыдущего блока)event_sequenceevent_sequenceevent_sequenceduration_hoursduration_hoursduration_hoursevent_countevent_countevent_countrework_countrework_countrework_countcostcostcostalgorithmkmeansopticsn_clusters44min_samples55random_state4242scale_numerictruetrueseparator>>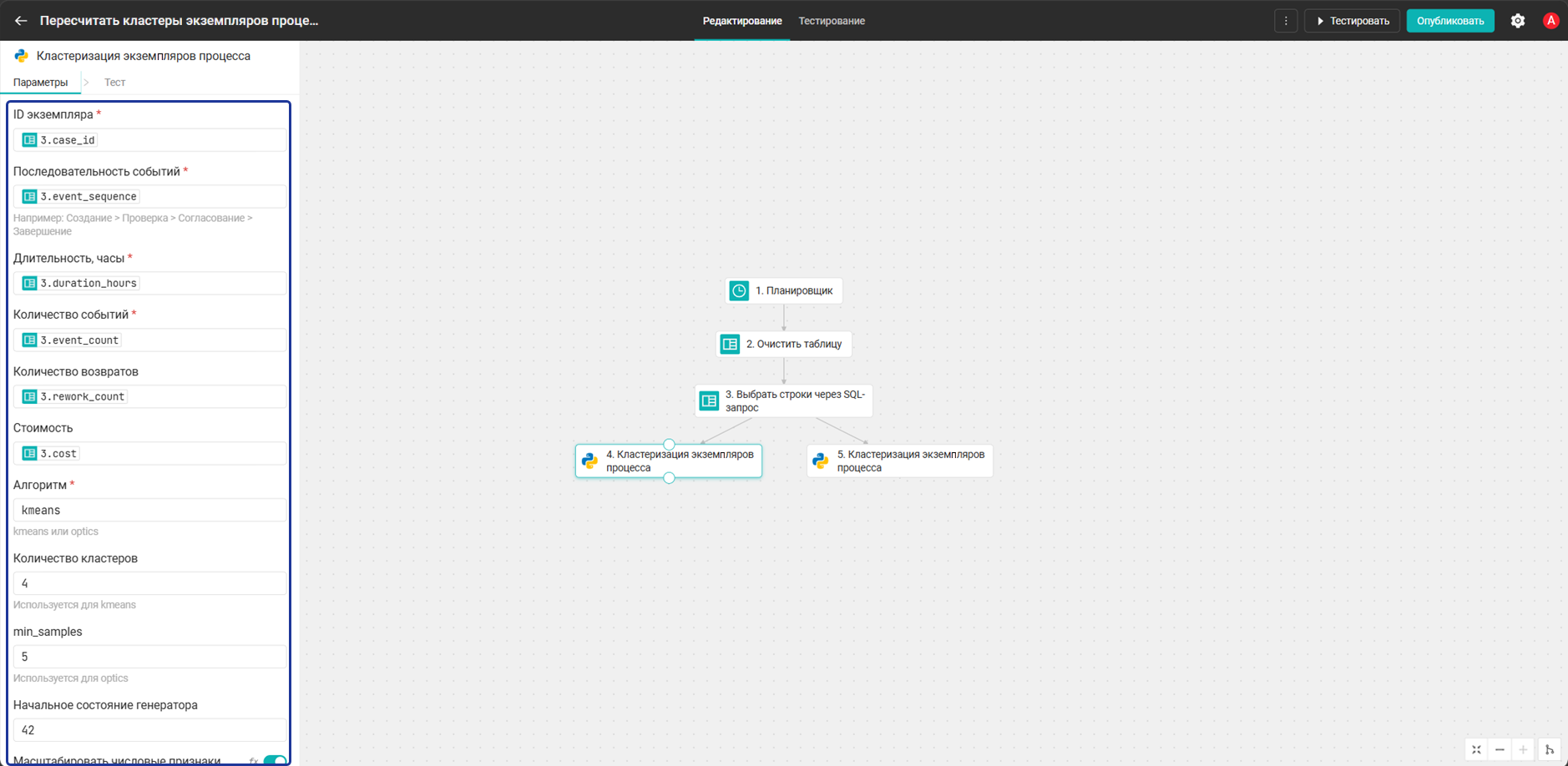
- Добавьте два блока Добавить строки. Каждый блок размещается сразу после Python-блока «Кластеризация экземпляров процесса» параллельно: первый блок Добавить строки — после Python-блока с алгоритмом kmeans, второй — после Python-блока с алгоритмом optics. Заполните поля каждого блока с помощью кнопки Автозаполнение полей выходными данными и укажите целевую таблицу
cluster_case_clusters. Протестируйте блоки.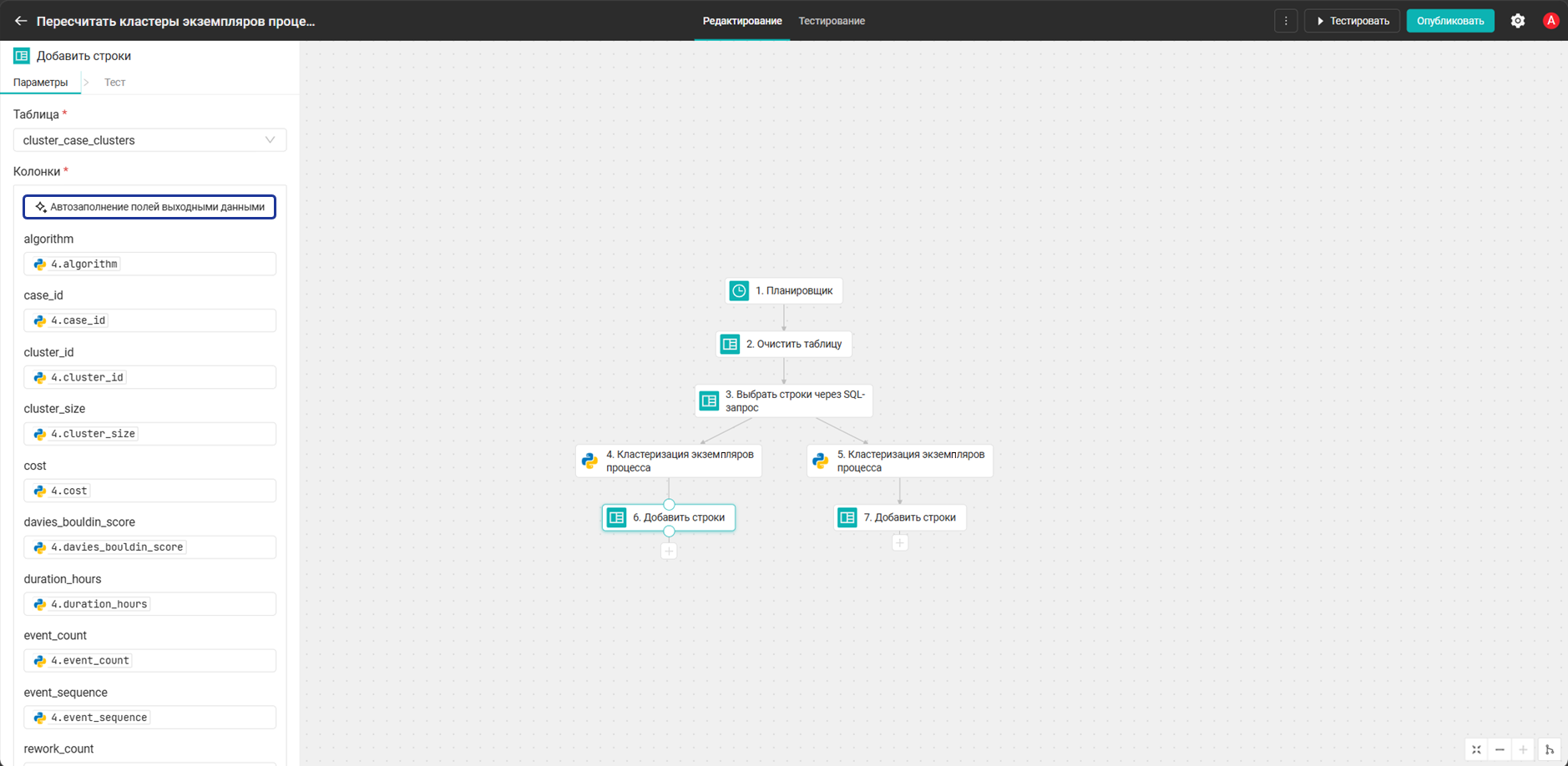
- Протестируйте скрипт полностью и опубликуйте его.
- После публикации активируйте скрипт.
- Перейдите в модель данных и проверьте, что таблица cluster_case_clusters заполнена данными.
Создание дашборда «Анализ кластеризации экземпляров процесса»
Чтобы визуализировать данные, собранные в таблицах cluster_case_clusters и process_event_log, создайте дашборд:
- Нажмите + Добавить → Дашборд.
- В открывшемся окне введите название дашборда Анализ кластеризации экземпляров процесса и нажмите Сохранить.
- Добавьте заголовок дашборда. Для этого добавьте виджет Текст и укажите название. Заголовок можно оформить с помощью Markdown и HTML-разметки, например:
> ## <font color="161E54"> **Анализ кластеризации экземпляров процесса**.
- Добавьте виджет Панель с показателями и настройте его:
- Мера:
Количество экземпляров в расчете→count("cluster_case_clusters"."case_id") - Мера:
Количество кластеров→countDistinct("cluster_case_clusters"."cluster_id") - Мера:
Коэффициент силуэта→max("cluster_case_clusters"."silhouette_score") - Мера:
Коэффициент Дэвиса–Болдина→max("cluster_case_clusters"."davies_bouldin_score")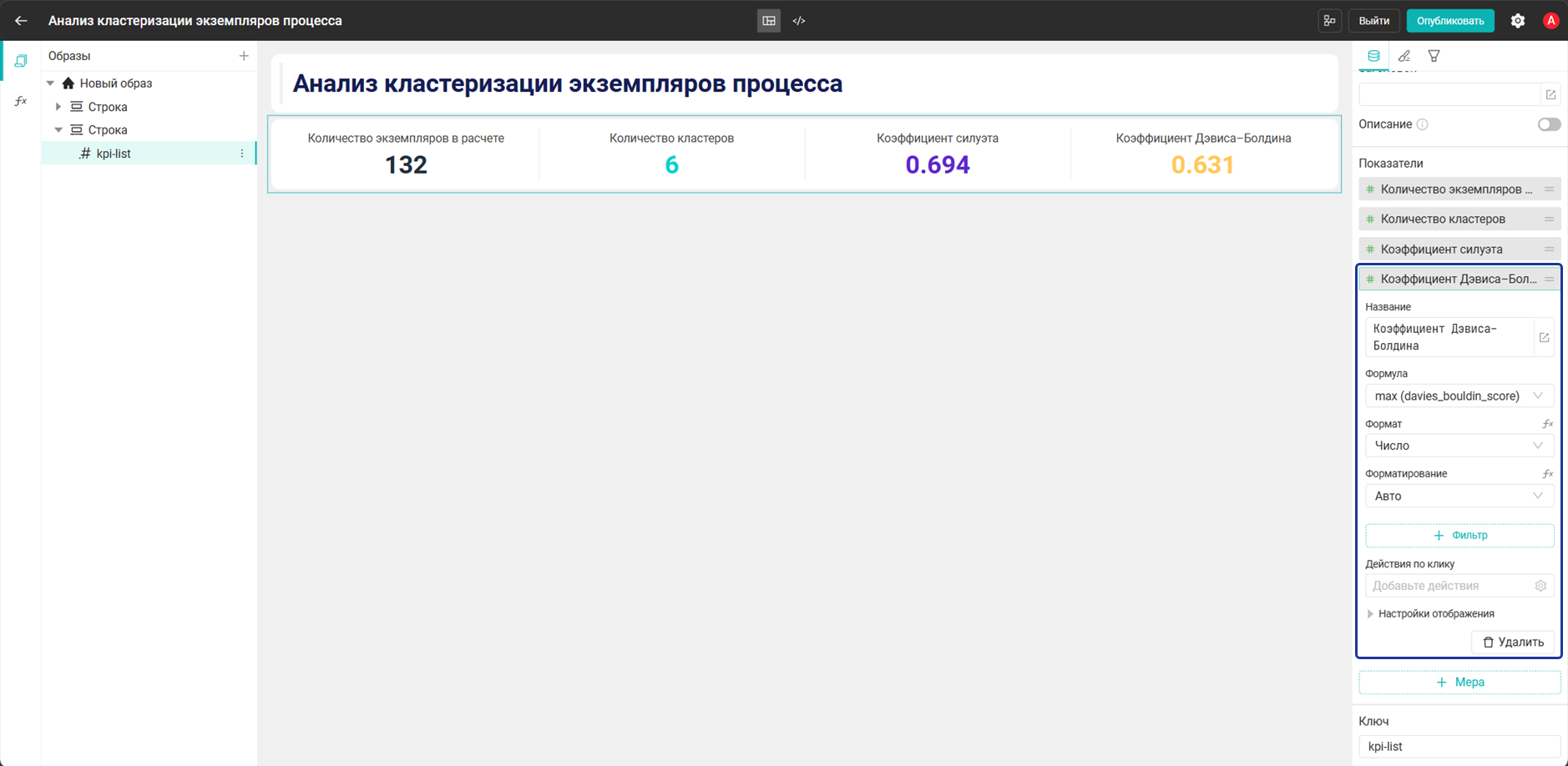
- Мера:
- Добавьте три виджета Фильтр и настройте их:
- Фильтр:
Кластер→"cluster_case_clusters"."cluster_id"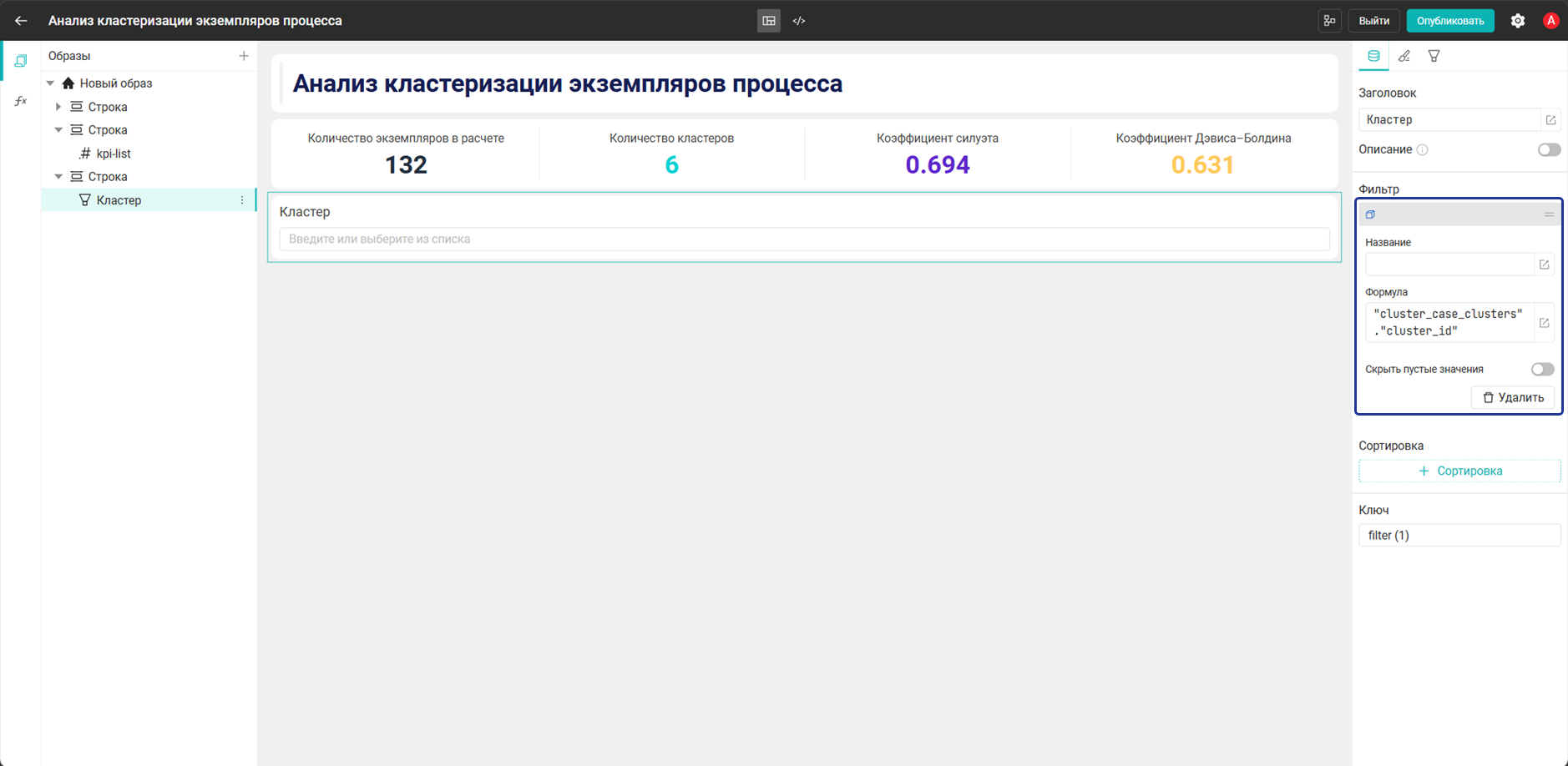
- Фильтр:
Алгоритм→"cluster_case_clusters"."algorithm"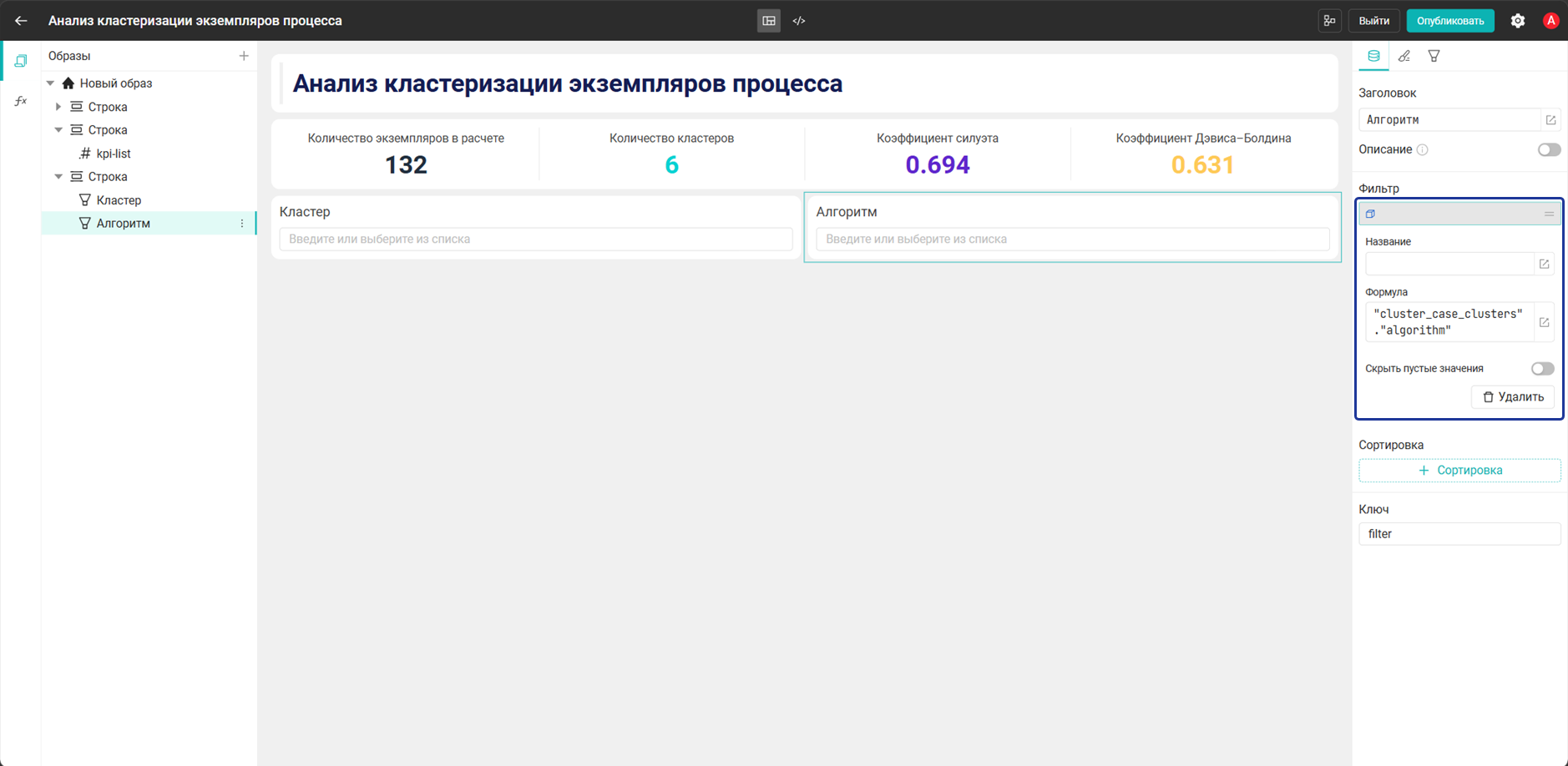
- Фильтр:
Событие→"cluster_case_clusters"."event_count"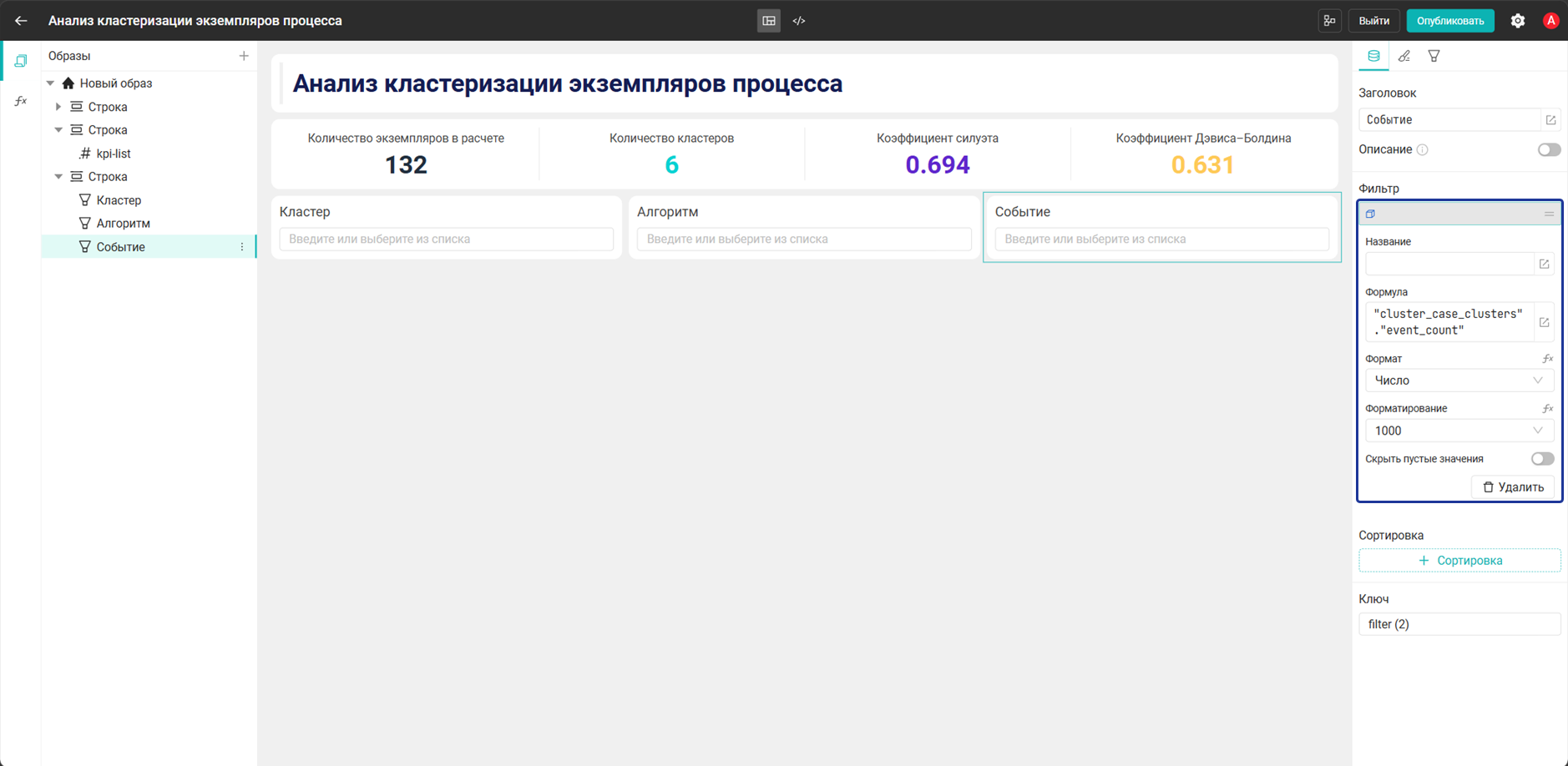
- Фильтр:
- Добавьте виджет Кольцевая диаграмма и настройте его:
- Разрез:
cluster_id→"cluster_case_clusters"."cluster_id" - Мера:
Количество case_id→count("cluster_case_clusters"."case_id")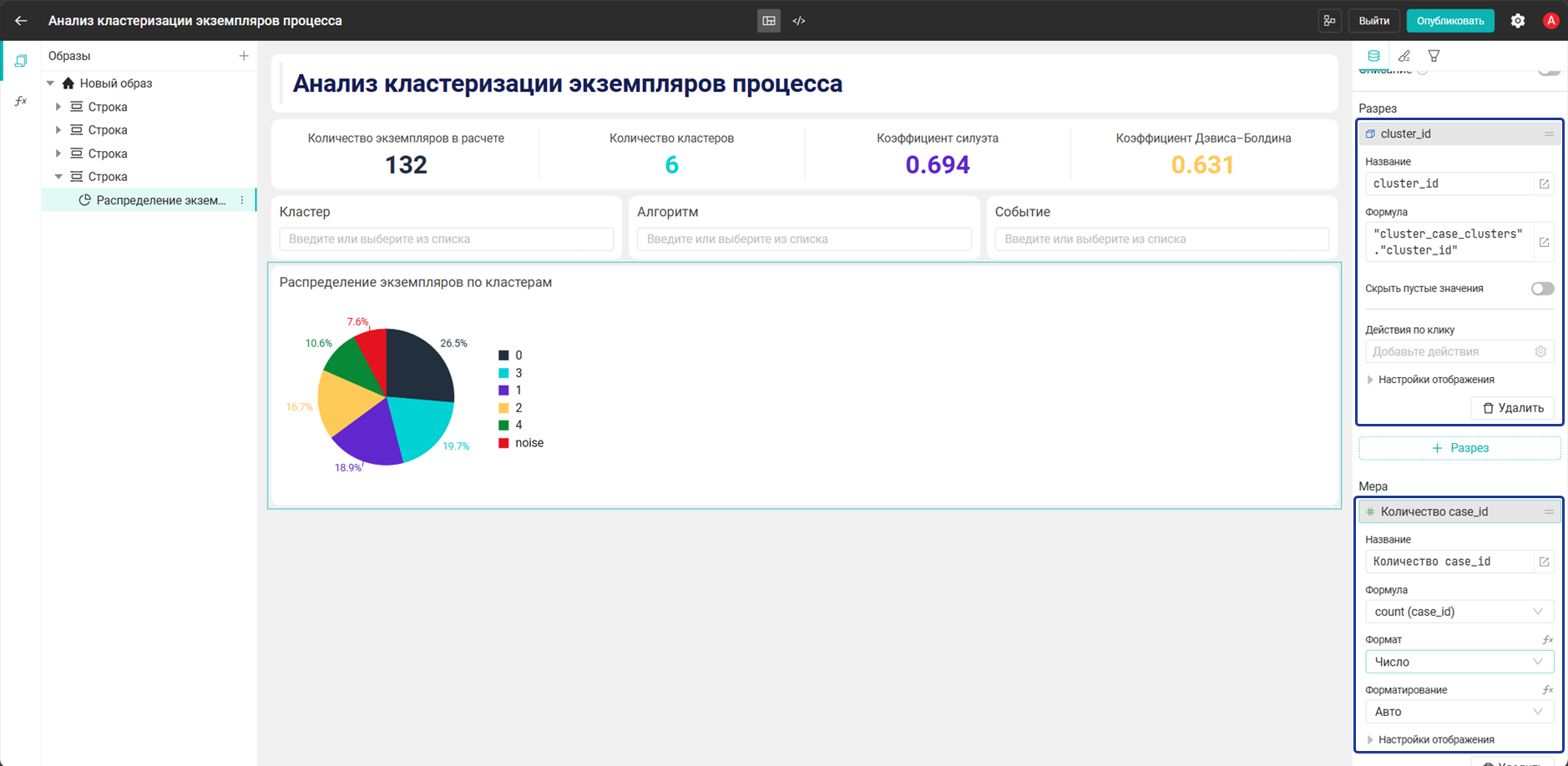
- Разрез:
- Добавьте виджет Комбинированная диаграмма и настройте его:
- Разрез:
cluster_id→"cluster_case_clusters"."cluster_id"
- Мера:
Среднее duration_hours→avg("cluster_case_clusters"."duration_hours")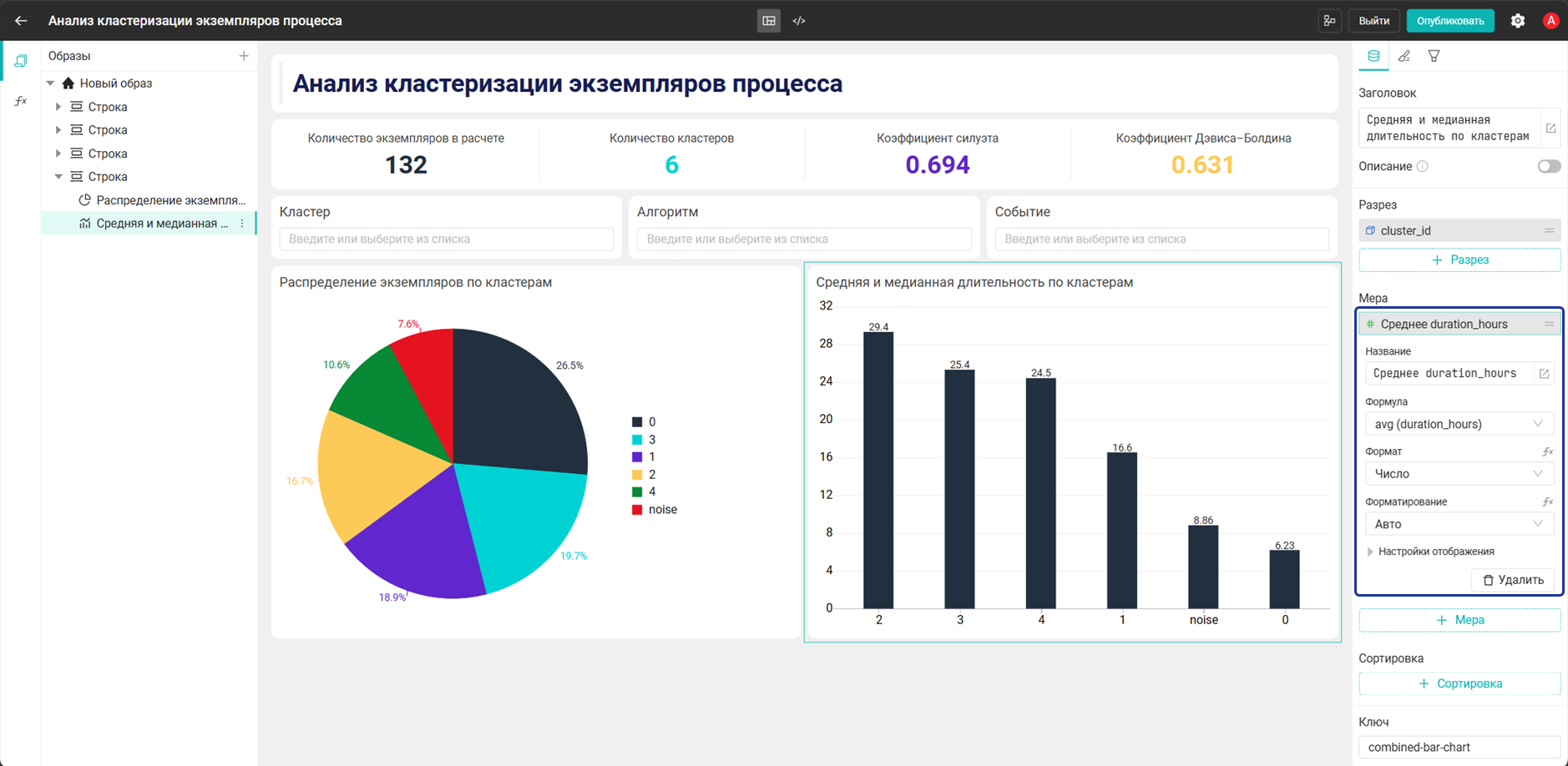
- Мера:
Медиана duration_hours→median("cluster_case_clusters"."duration_hours")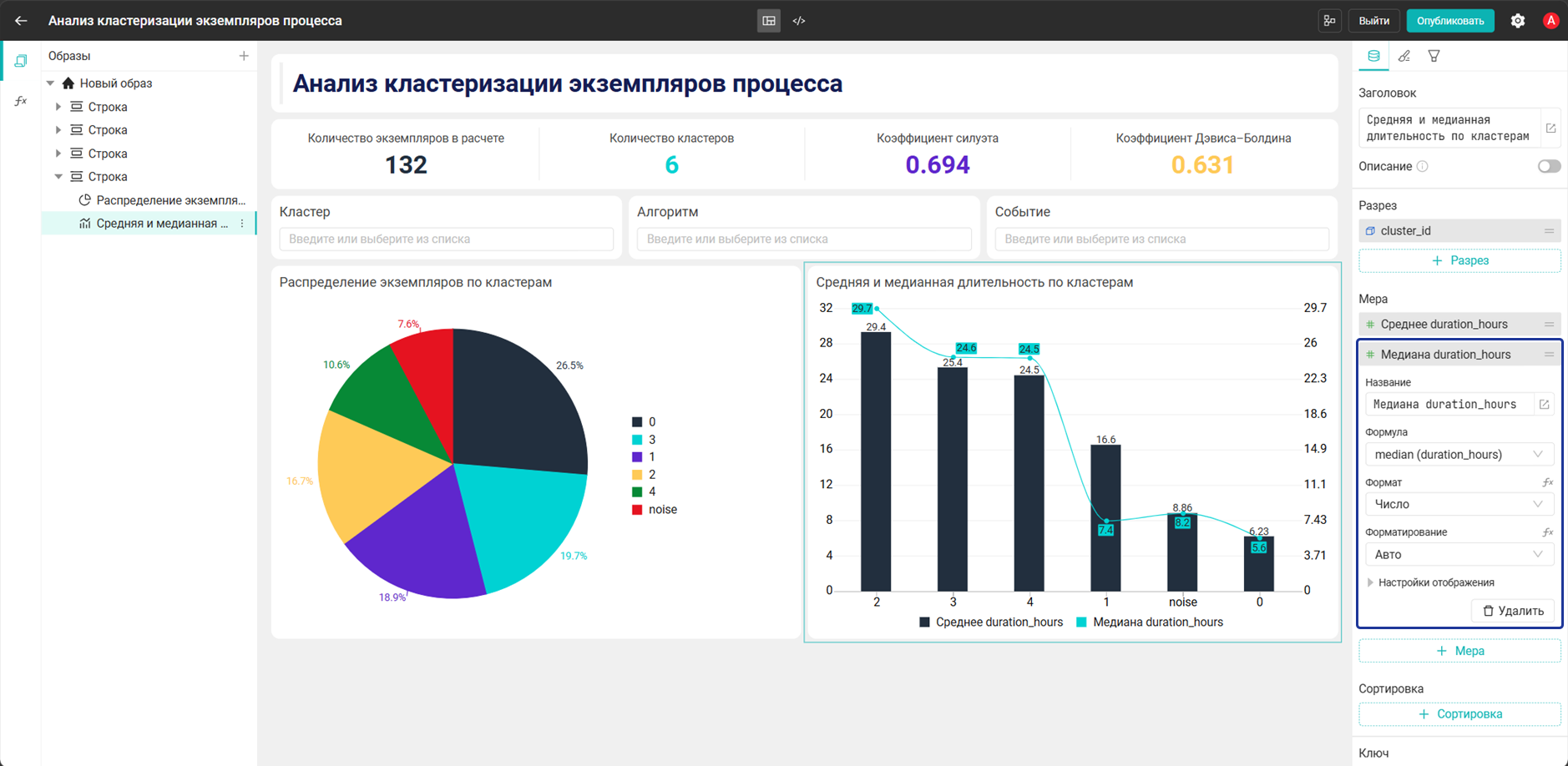
- Разрез:
- Добавьте виджет Столбиковая диаграмма и настройте его:
- Разрез:
cluster_id→"cluster_case_clusters"."cluster_id"
- Мера:
Сумма cost→sum("cluster_case_clusters"."cost")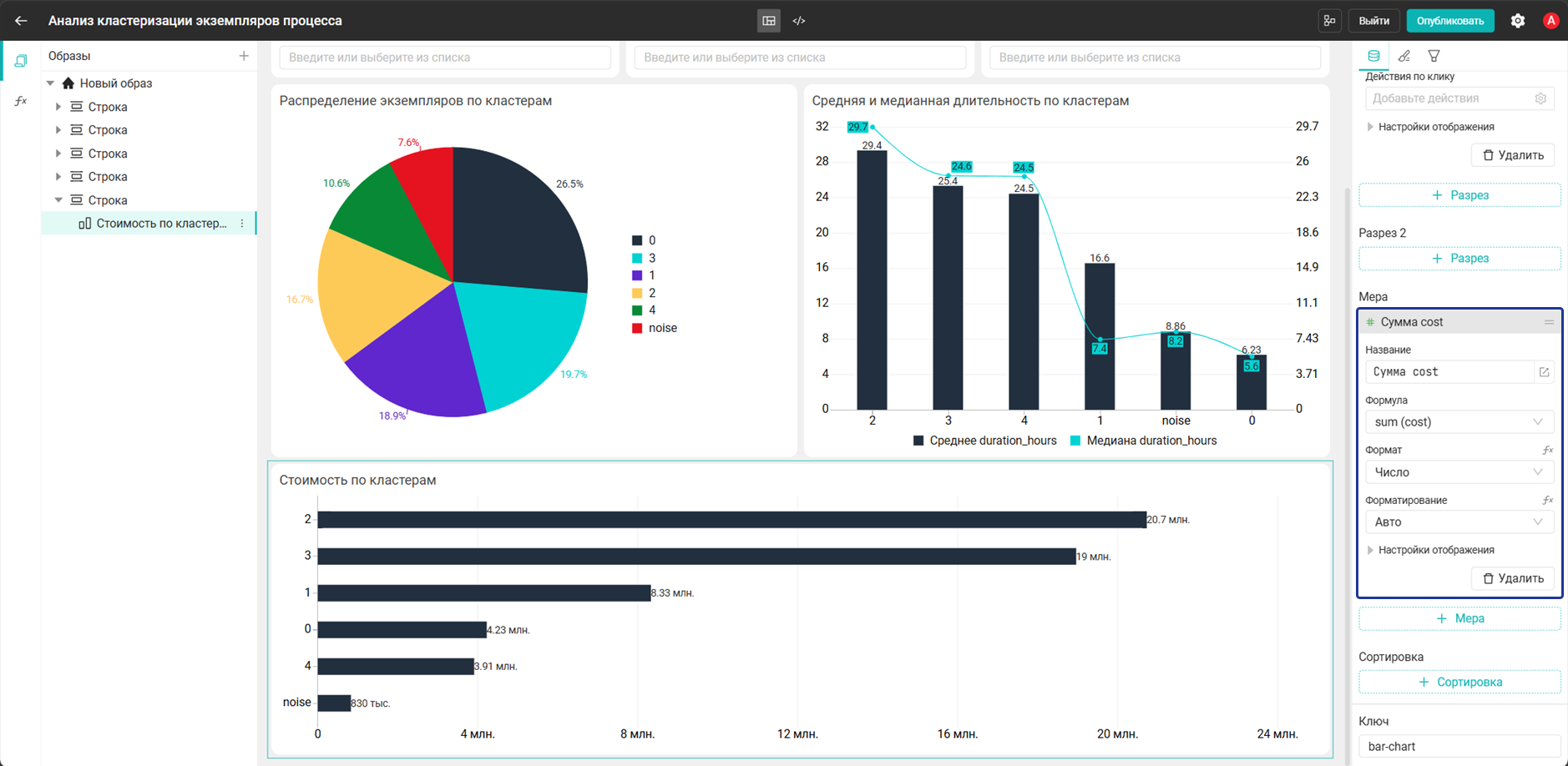
- Разрез:
- Добавьте виджет Таблица и настройте его:
- Разрез:
ID_кластера→"cluster_case_clusters"."cluster_id"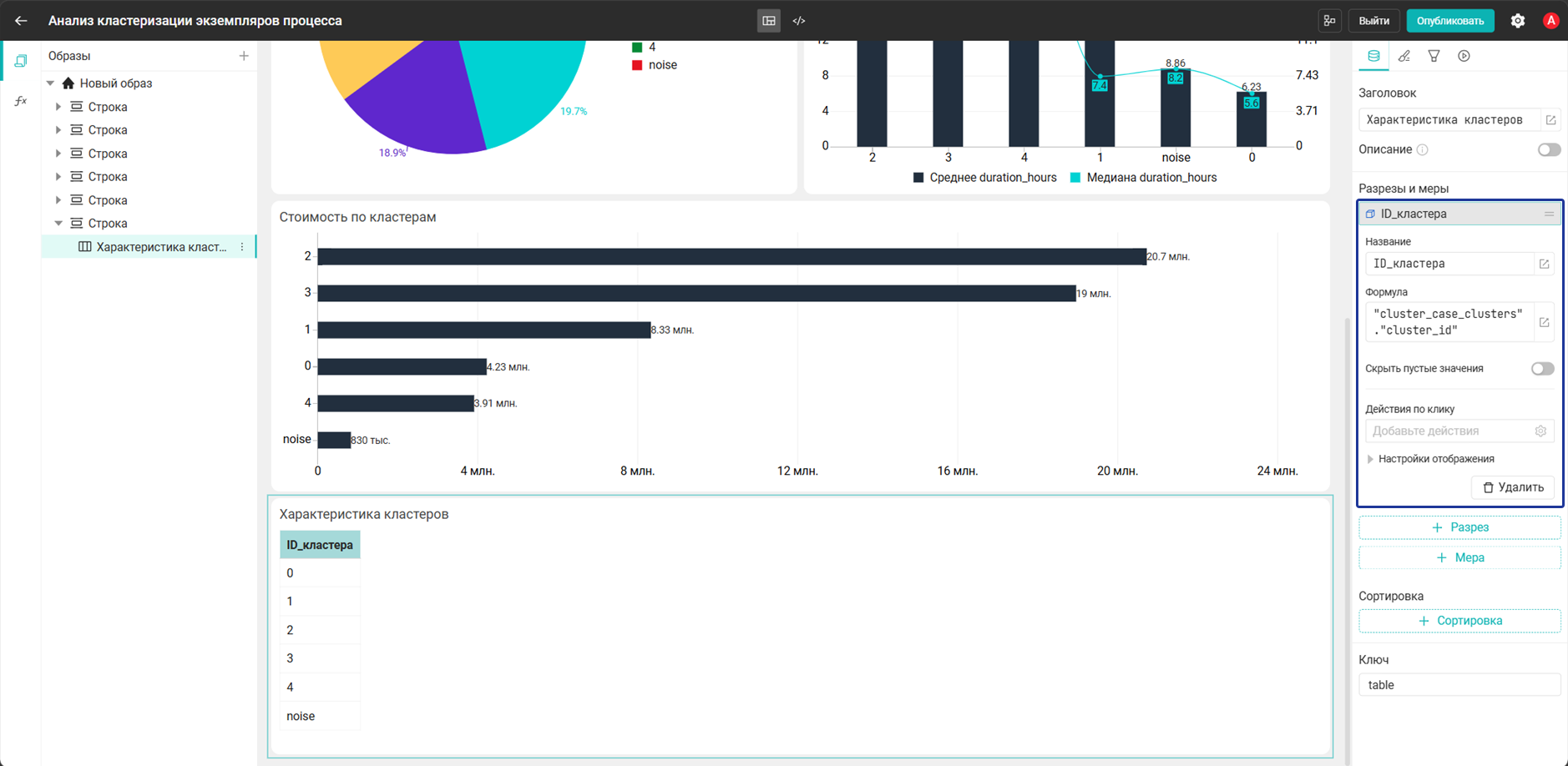
- Мера:
Число экземпляров→count("cluster_case_clusters"."case_id") - Мера:
Средняя длительность→avg("cluster_case_clusters"."duration_hours") - Мера:
Медианная длительность→median("cluster_case_clusters"."duration_hours") - Мера:
Среднее число событий→avg("cluster_case_clusters"."event_count") - Мера:
Стоимость→sum("cluster_case_clusters"."cost")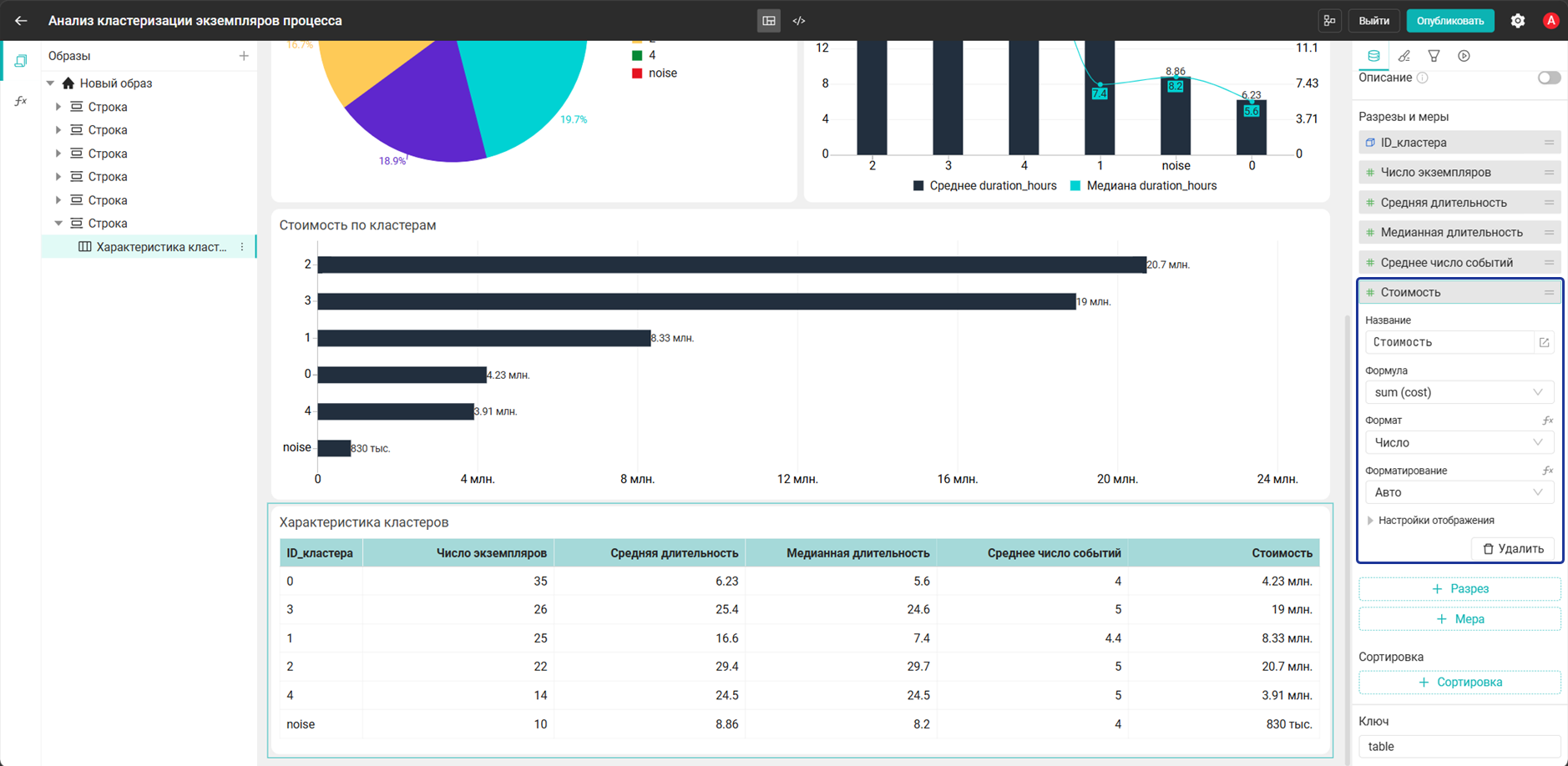
- Разрез:
- Добавьте виджет Воронка и настройте его:
- Этап процесса:
Создание запроса→Одно из событий→Create request - Этап процесса:
Проверка документов→Одно из событий→Check documents - Этап процесса:
Возврат на доработку→Одно из событий→Return for rework - Этап процесса:
Согласование менеджера→Одно из событий→Manager approval - Этап процесса:
Финансовое согласование→Одно из событий→Finance approval - Этап процесса:
Согласование директора→Одно из событий→Director approval - Этап процесса:
Завершение процесса→Одно из событий→Complete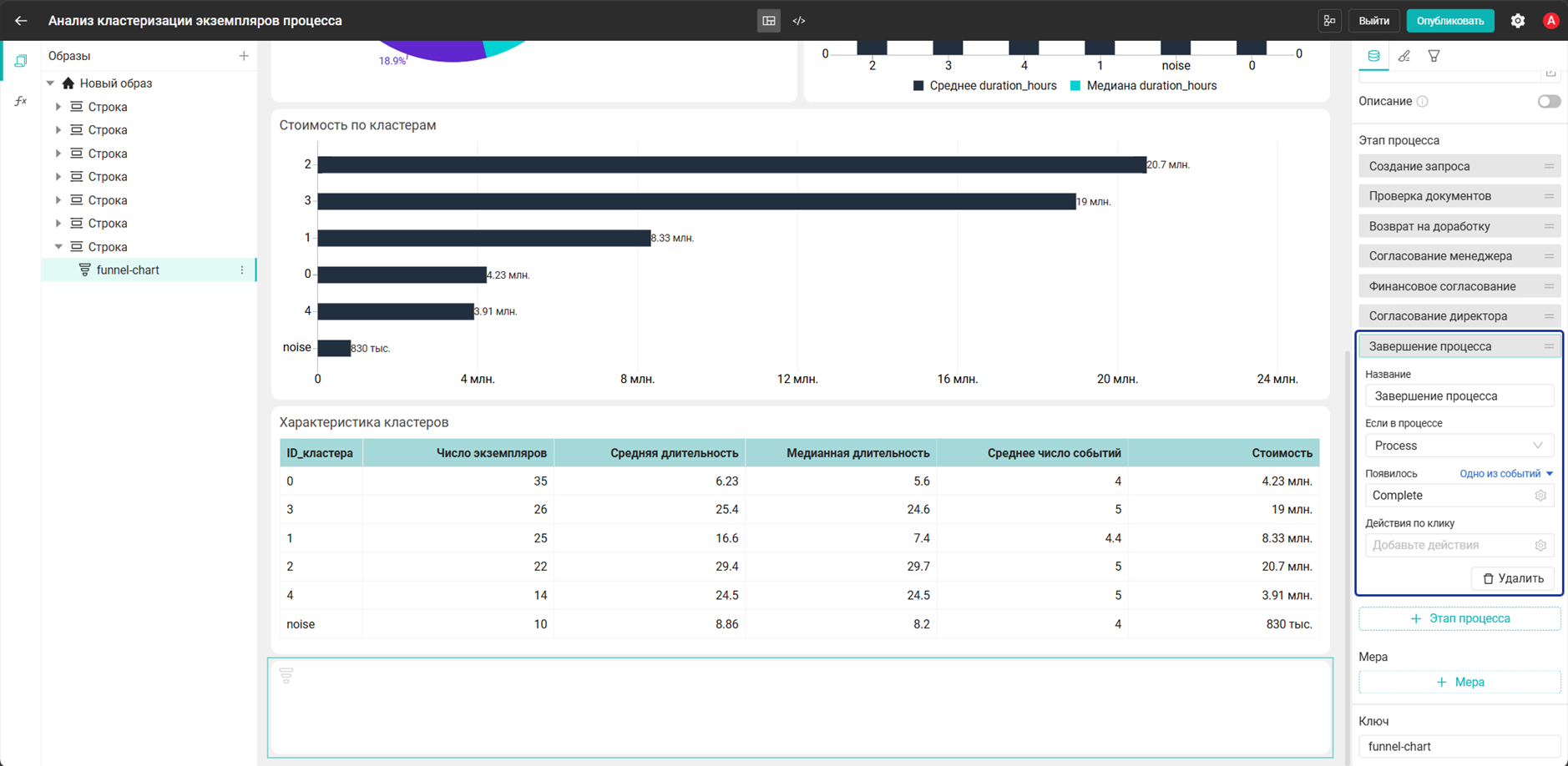
- Мера:
Количество событий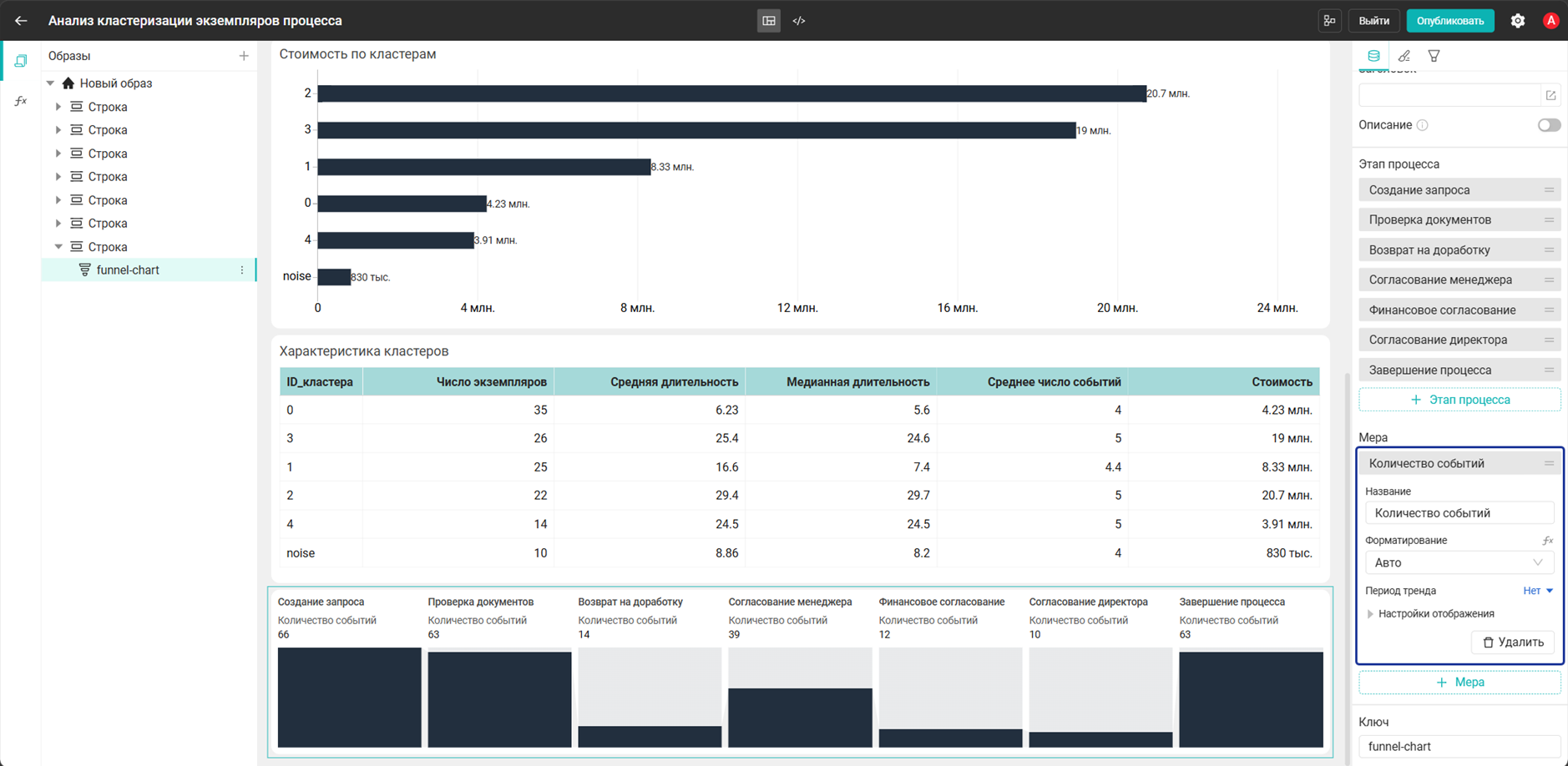
- Этап процесса:
Настройка процесса для карты процесса и сферы процессов
В системе доступны процессные виджеты, включая Карту процесса и Сферу процессов.
Чтобы использовать результат кластеризации для анализа процесса:
- Добавьте на дашборд виджет Карта процесса. Оставьте настройки по умолчанию.
- Показатели
Количество событий,Количество переработок,Количество переходовиМедианное времядобавятся автоматически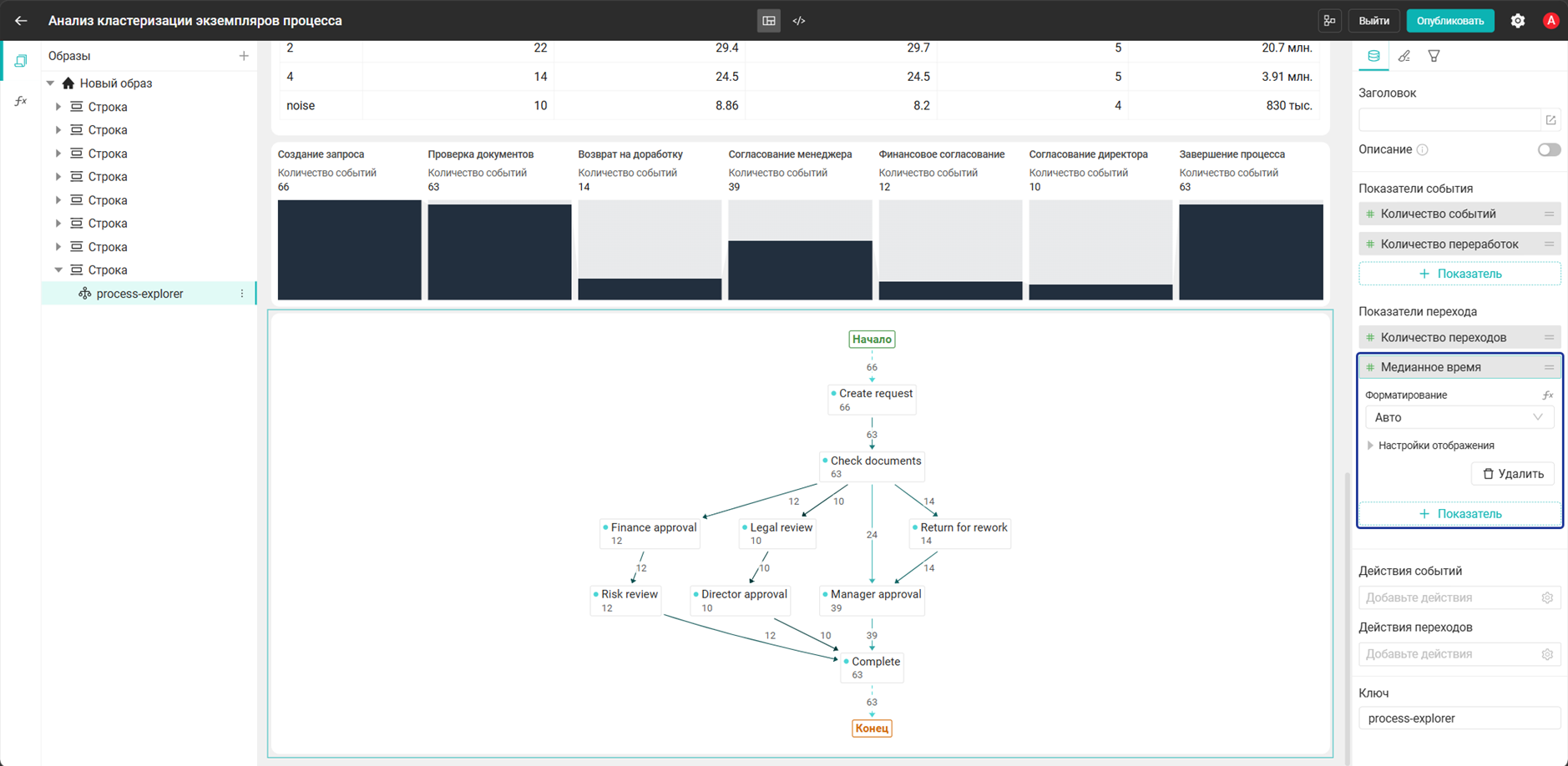
- Показатели
- Добавьте на дашборд виджет Сфера процессов и настройте его:
- Добавьте процесс:
Process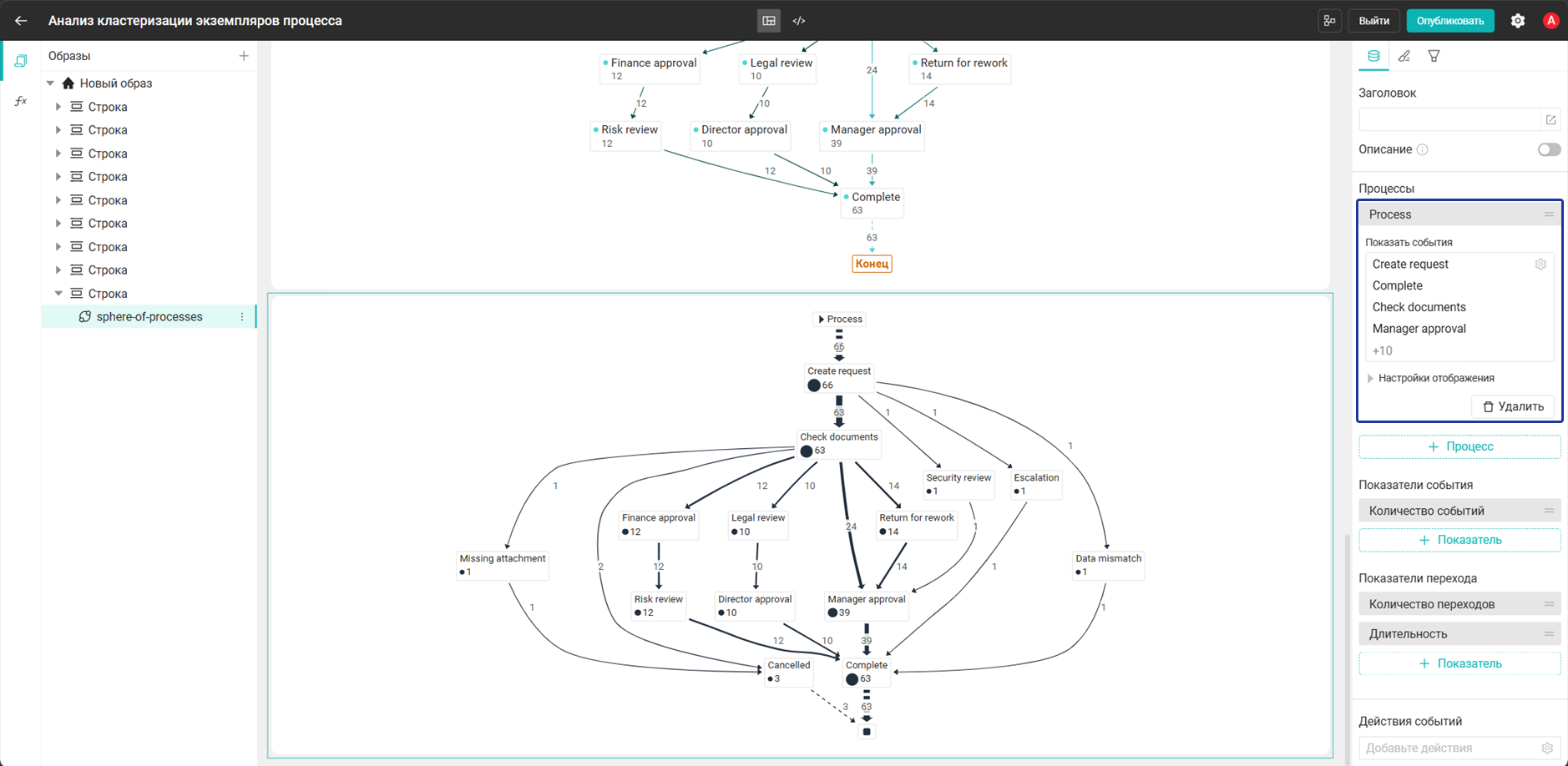
- Добавьте показатель:
Количество переработок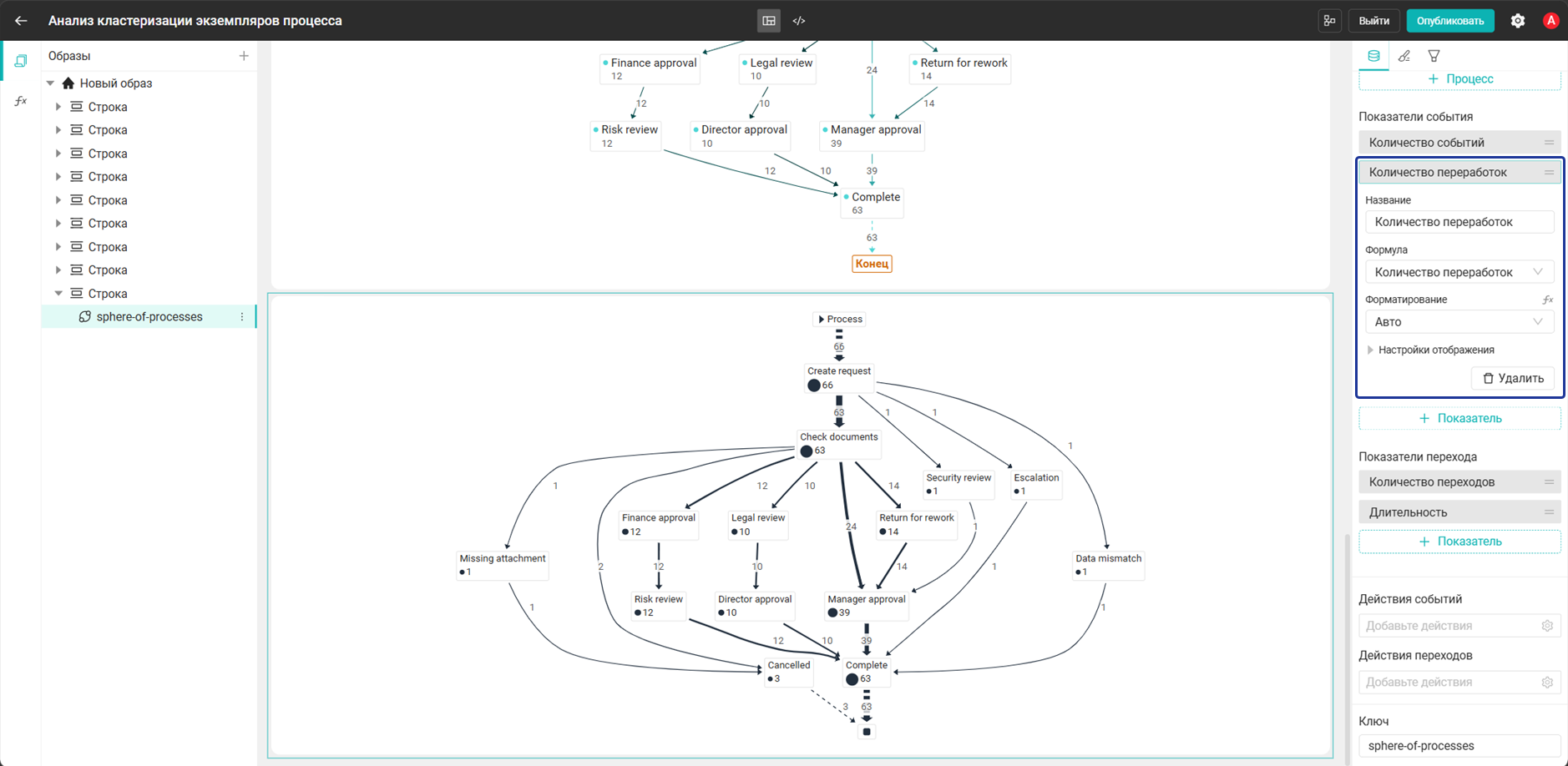
Количество событий,Количество переходовиДлительностьдобавятся автоматически. - Добавьте процесс:
В результате аналитик сначала выбирает интересующий кластер на диаграмме или в таблице, а затем сразу видит только соответствующий маршрут на Карте процесса.
- Выбранный кластер передается в Карту процесса и Сферу процессов через стандартную фильтрацию дашборда. Таблица
cluster_case_clustersсвязана с журналом событийprocess_event_logпо полюcase_id, поэтому при выборе значенияcluster_idв диаграмме, таблице или виджете Фильтр дашборд ограничивает набор экземпляров процесса, а процессные виджеты перестраиваются только по экземплярам выбранного кластера - Три виджета Фильтр нужны для разных уровней отбора. Фильтр Кластер позволяет выбрать группу экземпляров процесса для анализа, фильтр Алгоритм отделяет результаты
kmeansиoptics, а третий фильтр дополнительно сужает выборку внутри уже выбранного набора данных. Поэтому пользователь не настраивает отображение Карты процесса вручную: она автоматически принимает фильтры, примененные к дашборду
Публикация дашборда и настройка автообновления
После настройки виджетов:
- Включите автообновление дашборда.
- Чтобы опубликовать дашборд, нажмите Опубликовать.
- Проверьте, что после запуска скрипта обновляются все виджеты.
Анализ результатов и применение в работе
После запуска скрипта и обновления дашборда можно переходить к анализу результата. На этом этапе важно не только увидеть, что экземпляры процесса распределились по кластерам, но и понять, какие сценарии требуют отдельного внимания.
Рекомендуется анализировать результат в следующем порядке:
- Выберите алгоритм в фильтре Алгоритм и убедитесь, что дашборд показывает актуальный набор кластеров для выбранного расчета.
- Оцените качество разбиения по KPI:
- Коэффициент силуэта — чем выше значение, тем больше объекты внутри одного кластера похожи друг на друга и отличаются от объектов других кластеров
- Коэффициент Дэвиса–Болдина — чем ниже значение, тем лучше разделены кластеры
kmeansиoptics, но окончательное решение лучше принимать не только по метрикам, а по содержанию кластеров и маршрутам экземпляров процесса. - Сравните кластеры между собой по основным бизнес-характеристикам:
- По количеству экземпляров — чтобы отделить массовые сценарии от редких
- По средней и медианной длительности — чтобы найти затянутые сценарии
- По среднему числу событий — чтобы выявить сложные маршруты с дополнительными шагами
- По стоимости — чтобы выделить кластеры, связанные с дорогими кейсами
- Определите кластеры, которые стоит разбирать в первую очередь. Обычно в приоритет попадают:
- Крупные кластеры, если сценарий массовый и влияет на большую часть процесса
- Кластеры с повышенной длительностью, если задача состоит в сокращении времени прохождения
- Кластеры с возвратами на доработку, если нужно уменьшить количество повторных действий
- Кластеры с высокой стоимостью, если требуется отдельный контроль дорогих кейсов
- Уточните смысл выбранного кластера:
- Используйте Таблицу, чтобы сравнить характеристики кластера с остальными
- Используйте Воронку, чтобы понять, на каком этапе происходит основная потеря экземпляров
- Используйте Карту процесса, чтобы увидеть фактический маршрут после фильтрации по кластеру
- Используйте Сферу процессов, чтобы оценить, насколько сценарий разветвлен и где появляются дополнительные переходы
- Если для алгоритма
opticsпоявился кластерnoise, проанализируйте его отдельно. Такое значение показывает, что часть экземпляров процесса не вошла в устойчивые группы. В этом кластере часто оказываются редкие, смешанные или аномальные сценарии, которые полезно рассматривать как отдельный предмет анализа. - После интерпретации кластера сформулируйте рабочий вывод:
- Какой сценарий выявлен
- На каком этапе возникает отклонение
- Что именно делает этот сценарий проблемным: длительность, возвраты, стоимость или комбинация факторов
- Какой участок процесса нужно проверить в первую очередь
Результат кластеризации можно использовать не как итоговый отчет, а как инструмент приоритизации. Сначала аналитик находит кластер, который отличается по длительности, количеству возвратов или стоимости, затем открывает этот сценарий на Карте процесса и уже по схеме определяет участок процесса, который требует оптимизации.
После внесения изменений в процесс рекомендуется повторно запустить расчет и сравнить новый результат с предыдущим. Это позволяет проверить, уменьшились ли размер проблемного кластера, длительность прохождения и количество возвратов.
Пример рабочего процесса: анализ кластера с возвратами на доработку
Ситуация
Компания анализирует процесс согласования закупок. Для этого настроен дашборд Анализ кластеризации экземпляров процесса, который показывает результат расчета кластеров по экземплярам процесса.
В дашборде видно, что:
- Виджет Кольцевая диаграмма показывает распределение экземпляров по кластерам
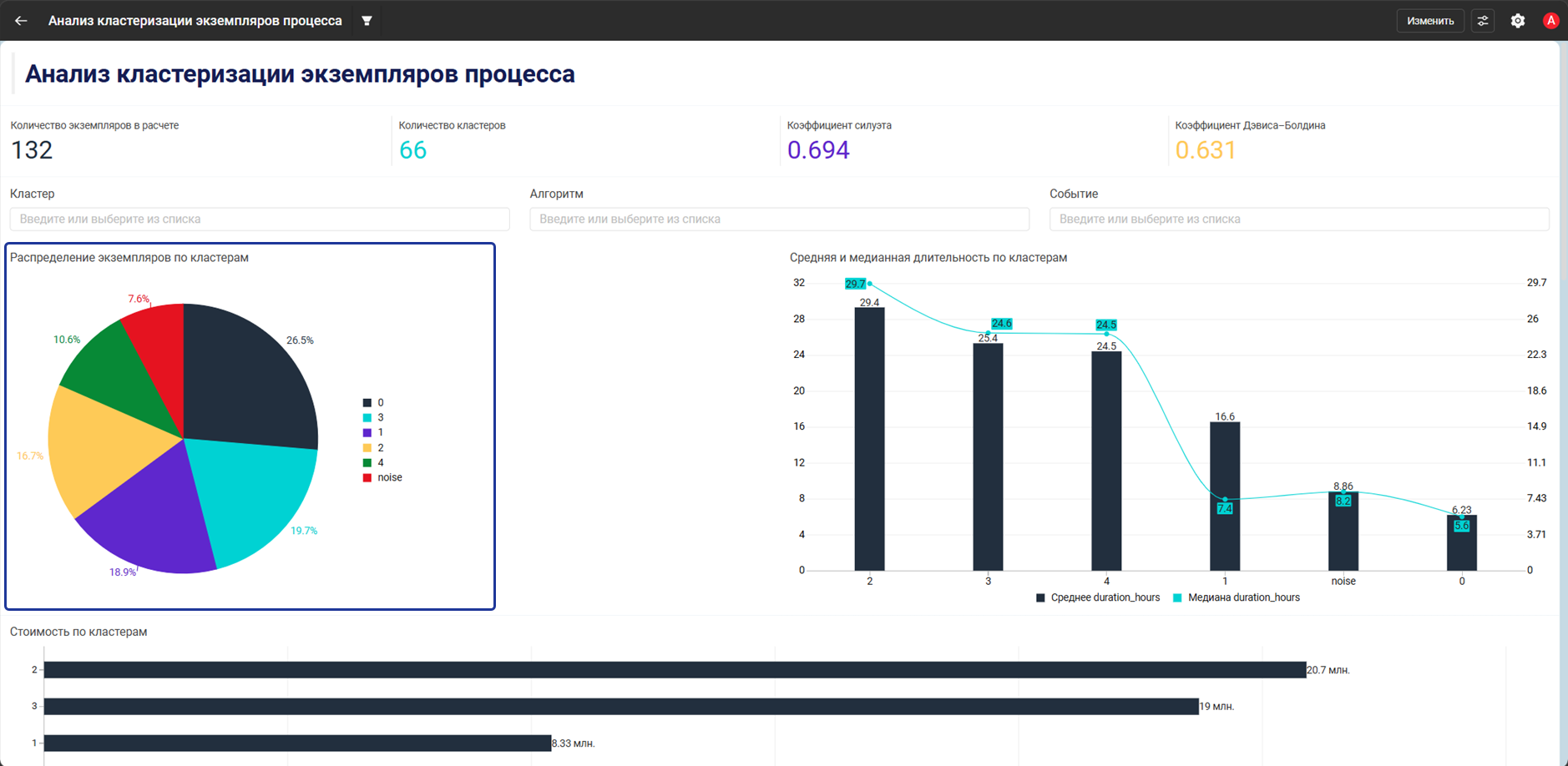
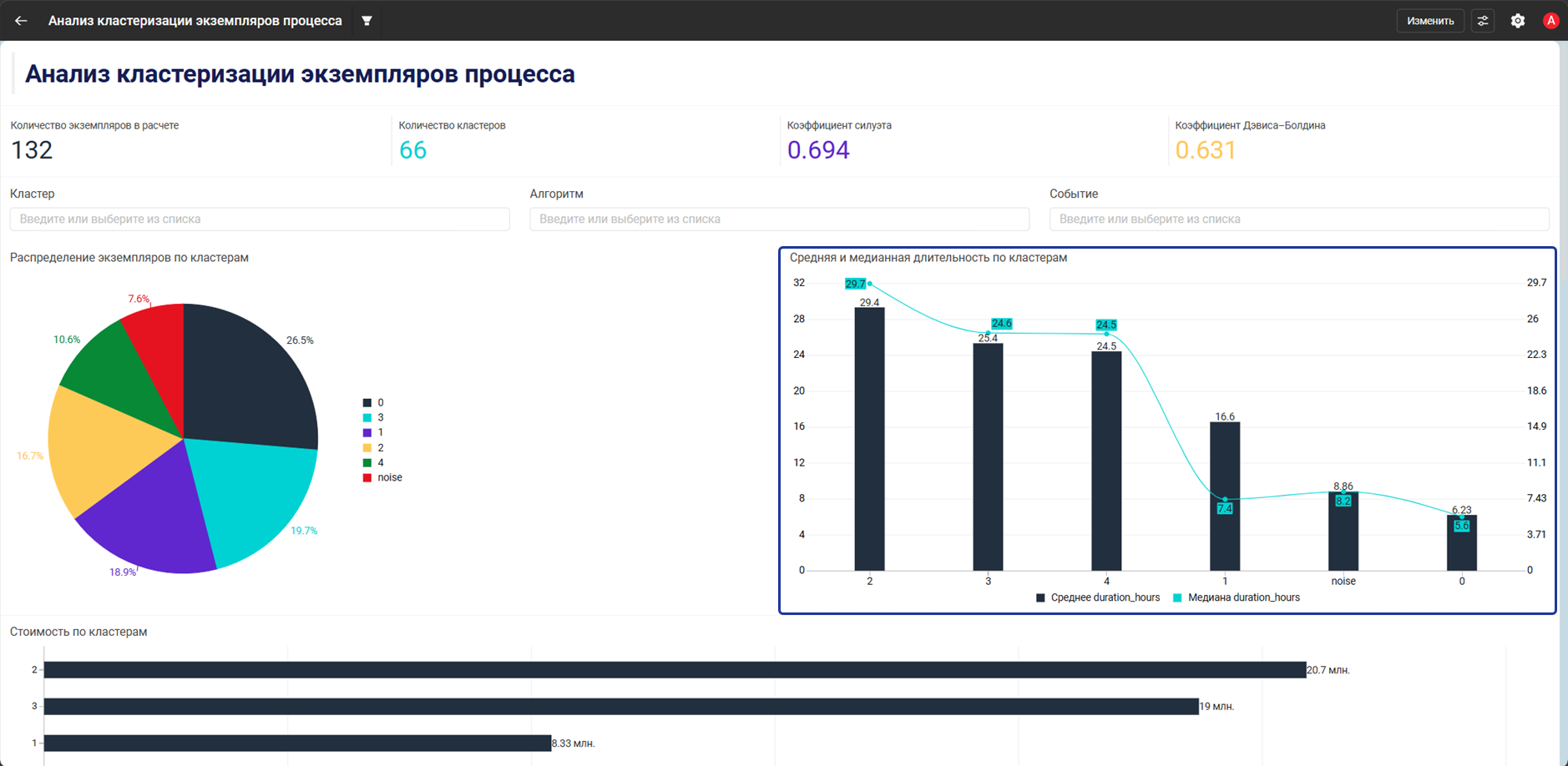
- Виджет Комбинированная диаграмма показывает среднюю и медианную длительность по кластерам
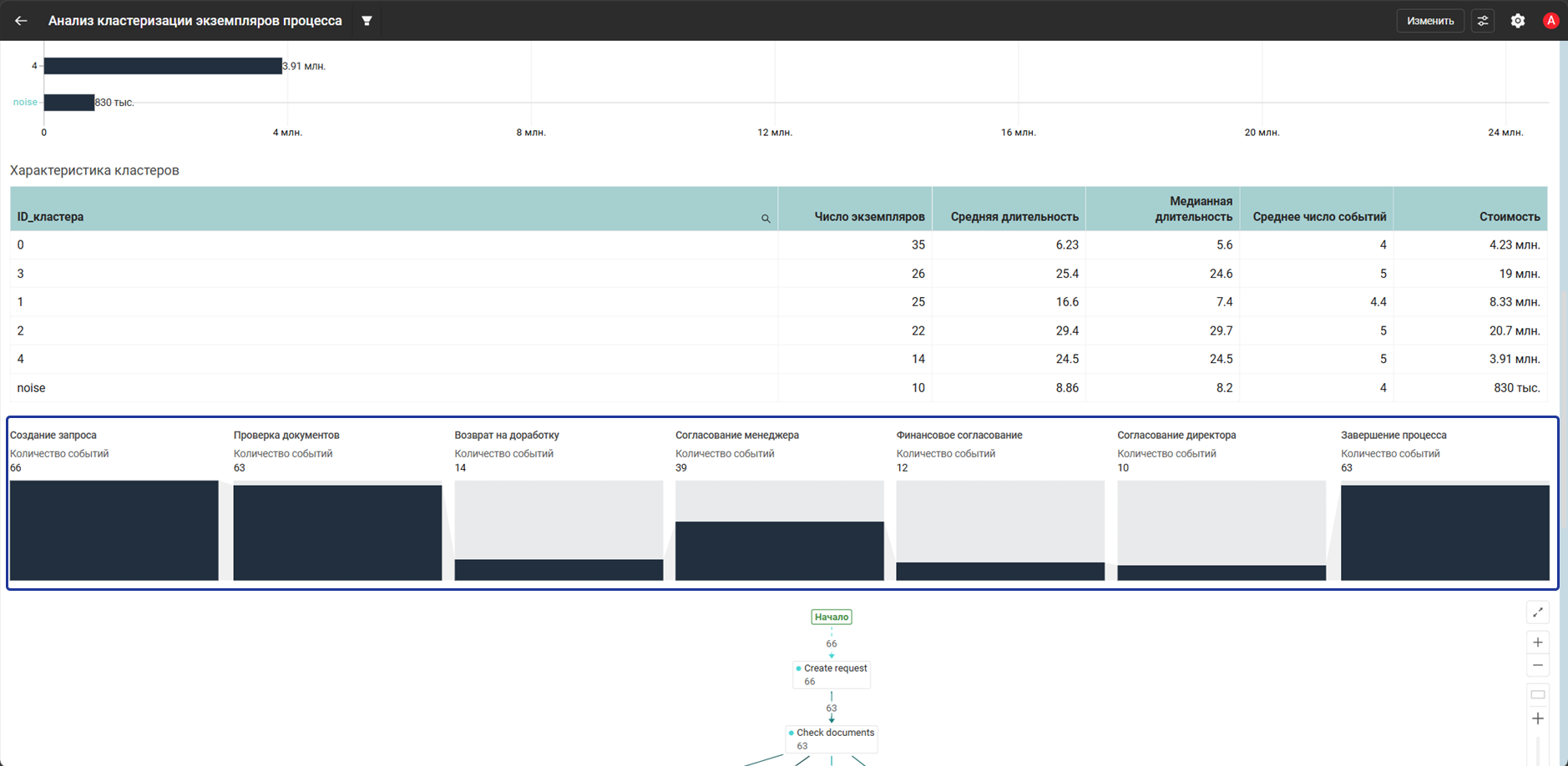
- Виджет Таблица показывает характеристики кластеров: число экземпляров, среднюю и медианную длительность, среднее число событий и стоимость
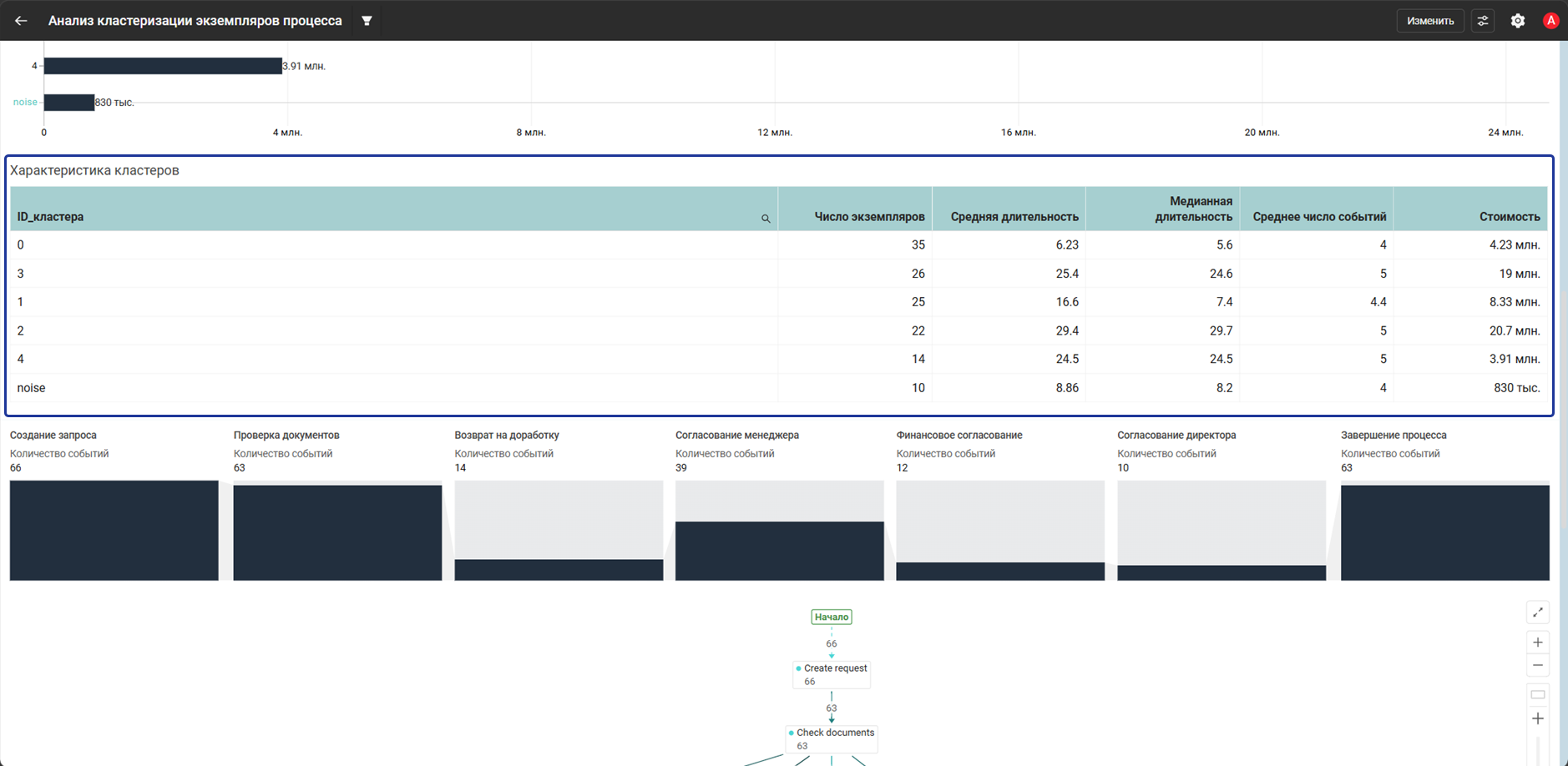
- Виджет Воронка показывает прохождение по ключевым этапам процесса:
Create requestCheck documentsReturn for reworkManager approvalFinance approvalDirector approvalComplete
- Виджеты Карта процесса и Сфера процессов связаны с результатом кластеризации через поле
case_id, поэтому при выборе кластера аналитик сразу видит соответствующий маршрут процесса
В процессе согласования часть заявок проходит по базовому сценарию, а часть возвращается на доработку после проверки документов. Из-за этого появляются дополнительные события, увеличивается длительность кейсов и формируется отдельный сценарий исполнения экземпляра процесса.
Формирование сценария с возвратами
- Создание заявки — сотрудник создает заявку на закупку и отправляет ее в процесс
- Проверка документов — заявка попадает на этап
Check documents - Возврат на доработку — если в заявке не хватает данных или вложений, она переходит на этап
Return for rework - Повторная проверка — после исправления заявка снова возвращается на
Check documents - Дальнейшее согласование — только после успешной проверки заявка идет дальше по этапам согласования и завершается на
Complete
Пересчет кластеров
- При запуске скрипта кластеризации:
- Для каждого экземпляра процесса собираются последовательность событий, длительность, количество событий, количество возвратов и стоимость
- Поле
rework_countучитывает возвраты на доработку как один из признаков проблемного сценария - Экземпляры процесса с повторяющимся фрагментом
Check documents → Return for rework → Check documentsвыделяются в отдельный кластер - Результат записывается в таблицу
cluster_case_clustersи становится доступен на дашборде
Отображение результата на дашборде
- После пересчета аналитик видит, что один из кластеров отличается от остальных:
- По длительности — на комбинированной диаграмме он находится среди самых долгих сценариев
- По числу событий — в таблице у него больше событий, чем у базового маршрута
- По характеру маршрута — воронка и процессные виджеты показывают наличие возврата на доработку
- При выборе этого кластера на Кольцевой диаграмме или в Таблице:
- Остальные виджеты автоматически фильтруются
- На Карте процесса остается только маршрут выбранного кластера
- В Сфере процессов становится виден соответствующий сценарий исполнения экземпляра процесса
Возможные действия аналитика процесса
- Аналитик процесса:
- Открывает дашборд Анализ кластеризации экземпляров процесса
- Сравнивает кластеры по длительности и числу событий
- Выбирает кластер, связанный с возвратами на доработку
- Проверяет Воронку и видит, что отклонение возникает после этапа
Check documents - Открывает Карту процесса и видит маршрут с возвратом на
Return for rework - Открывает Сферу процессов и убеждается, что это не единичный случай, а повторяющийся сценарий исполнения экземпляра процесса
Результат: аналитик делает вывод, что проблемный участок находится на этапе проверки документов. Именно здесь возникает возврат на доработку, который увеличивает длительность процесса и число событий в экземпляре процесса.
Дополнительные бизнес-действия
- Владелец процесса — проверяет, по каким причинам заявки чаще всего возвращаются после
Check documents - Руководитель закупок — уточняет требования к составу документов и правилам заполнения заявки
- Аналитик процесса — после изменений повторно запускает расчет кластеров и сравнивает результат с предыдущим
- Команда процесса — отслеживает, уменьшился ли размер кластера с возвратами и сократилась ли длительность его прохождения
Ключевые преимущества, продемонстрированные в процессе
- Автоматизация — сценарий с возвратами выявляется без ручного разбора всех экземпляров процесса
- Наглядность — кластер можно сравнить на диаграммах, в таблице, на воронке и на процессных виджетах
- Быстрый переход к анализу причины — после выбора кластера аналитик сразу видит соответствующий маршрут на Карте процесса
- Приоритизация улучшений — команда понимает, какой участок процесса требует оптимизации в первую очередь
- Повторная проверка эффекта — после изменений можно пересчитать кластеры и сравнить результат
Преимущества для пользователя
| Роль | Польза |
|---|---|
| Аналитик процесса | Быстро находит кластер, в котором есть возвраты на доработку, и сразу видит соответствующий маршрут на Карте процесса |
| Владелец процесса | Понимает, на каком этапе формируется отклонение и какой сценарий сильнее всего влияет на длительность процесса |
| Руководитель закупок | Получает основание для изменения правил проверки заявки и состава обязательных документов |
| Операционный менеджер | Может сравнить результат до и после изменений и оценить, уменьшился ли проблемный кластер |
Насколько полезной была статья?