Примеры пользовательских реализаций в Python SDKBETA
Для демонстрации того, как можно расширять функциональность системы, создавая собственные логические элементы — от простых арифметических блоков до моделей машинного обучения, ниже собраны готовые примеры пользовательских реализаций. Используйте эти шаблоны как основу для своих разработок.
Примеры реализаций Python-блоков
Группа Python
Группа, содержащая в себе некоторые блоки автоматизации.
Структура группы в примере ниже:
get_uuid()— возвращает уникальный идентификатор группыuuidгруппы рекомендуется задавать в форматеусловное_имя_группы_UUID4_хэшдля обеспечения уникальности с сохранением описательной функции идентификатора
get_icon()— возвращает путь ассоциированной с группой относительно папки скриптаget_name()— возвращает варианты локализации имени группы в виде словаряget_category()— возвращает категорию группы, используется для группировки в интерфейсе
from sdk.abstract_group import AbstractGroup
import os
class ExampleGroup(AbstractGroup):
def __init__(self):
super().__init__()
def get_uuid(self):
return "python_group_ed4bf34d-b75c-4ebb-968d-344e0f9c5ec5"
def get_name(self):
return {
"en" : "Python group",
"ru" : "Группа Python",
}
def get_category(self):
return "tools"
def get_icon(self):
return os.path.join(os.path.dirname(os.path.realpath(__file__)), "python_group_ed4bf34d-b75c-4ebb-968d-344e0f9c5ec5.png")
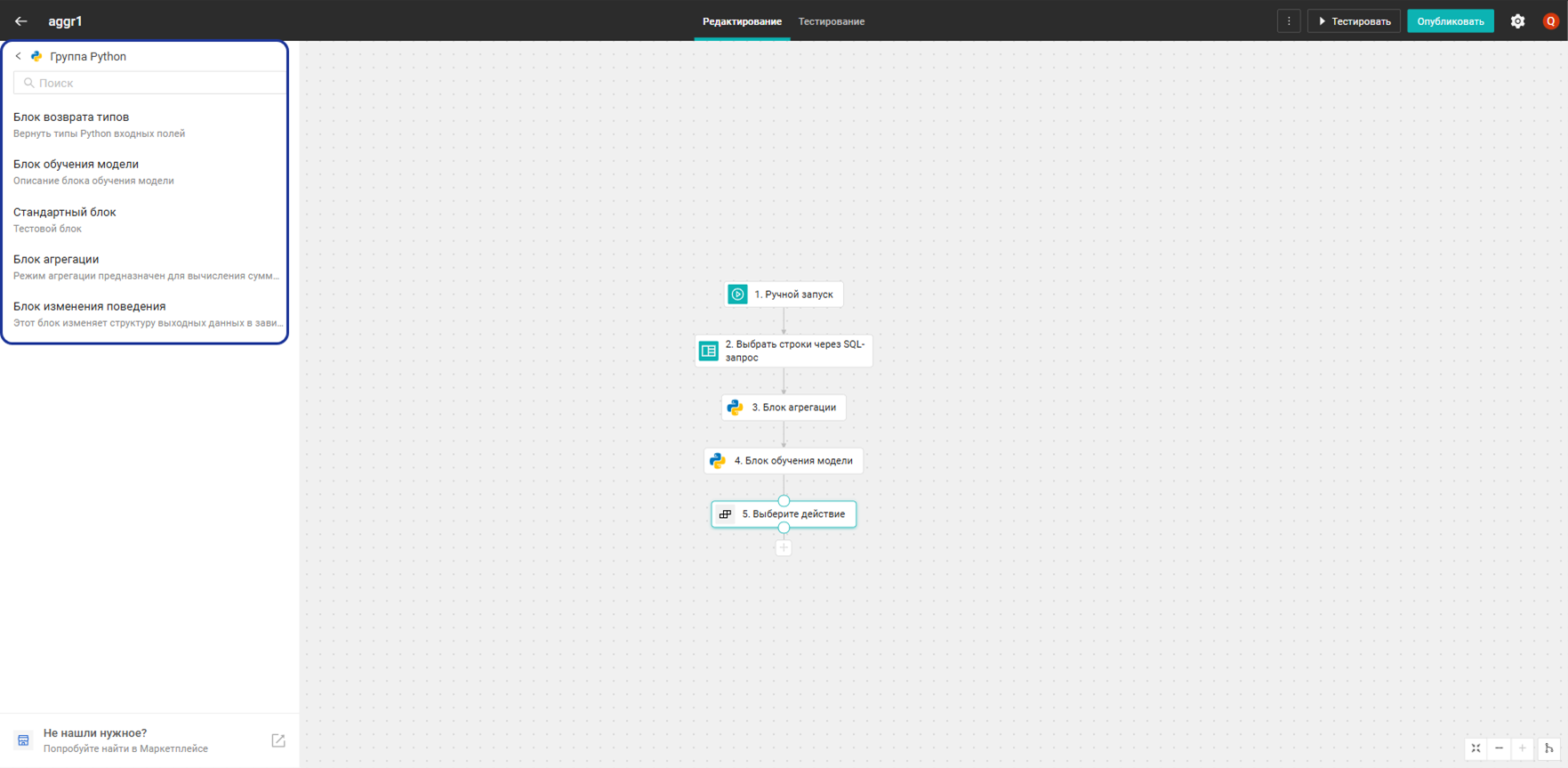
Блок агрегации
Блок суммирует значения колонки value в разрезе колонки name. Аналогичен поведению groupby в SQL.
Структура блока в примере ниже:
get_uuid()- Возвращает uuid блока в результате метода
get_info_outputимеет форматусловное_имя_блока_UUID4_хэшдля отличия блоков с одинаковыми условными именами
- Возвращает uuid блока в результате метода
get_compatible_connections()- Возвращает список совместимых с блоком подключений. Эти подключения должны быть имплементациями абстрактного подключения и импортированы через секцию импорта
get_type()- Возвращает тип блока
get_name()- Возвращает варианты локализации имени блока в виде словаря
get_description()- Возвращает локализованное описание блока в виде словаря
get_fields()- Возвращает строковое представление JavaScript описания полей пользовательских интеграций
get_block_output_options()- Возвращает список возможных конфигураций выходных полей
get_block_aggr_mode()- Возвращает булево значение True
get_block_input()- Возвращает поля, которые возвращаются в результате вызова метода
get_fields - Названия типов данных соответствуют типам данных Java
- Возвращает поля, которые возвращаются в результате вызова метода
get_block_output()- Возвращает словарь со структурами выходных переменных автоматизации
- Названия типов данных соответствуют типам данных:
- Long
- LongArray
- Double
- DoubleArray
- Boolean
- BooleanArray
- String
- StringArray
- BigInteger
- BigIntegerArray
- BigDecimal
- BigDecimalArray
- DateTime
- DateTimeArray
- Object
- ObjectArray
- FileContent
process_data()- Входная переменная
dataметодаprocess_dataможет содержать ключи:connection_data- содержит словарь форматаимя_поля_подключения:значение_поляиз переданного подключения (опционален)block_data- содержит список, элементом которого является строка данных в формате "имяполяблока":"значение_поля" (обязательно присутствует)
- Результат вызова метода функции. Уровни вложенности по порядку:
- Агрегационный режим (глубина вложенности=2, так как нет связи с входящими записями):
- 1 уровень - каждый элемент соответствует одной результирующей исходящей записи. Набор элементов представляет собой ответ на входящую запись
- 2 уровень - каждый элемент соответствует значению поля исходящей записи. Порядок и типы полей соответствуют описанию в
output_variables
- Агрегационный режим (глубина вложенности=2, так как нет связи с входящими записями):
- Входная переменная
from sdk.abstract_block import AbstractBlock
import pandas as pd
class AggregateBlock(AbstractBlock):
def __init__(self):
pass
def get_uuid(self):
return "aggr_block_4152eecc-fa15-4102-911d-f76044ac5445"
def get_type(self):
return "action"
def get_name(self):
return {
"en" : "Testing block info",
"ru" : "Блок агрегации",
}
def get_description(self):
return {
"en" : "Testing block description",
"ru" : "Режим агрегации предназначен для вычисления суммы значений sum(`value`) в разрезе имен (ключ `name`)",
}
def get_compatible_connections(self):
return []
def get_optionals(self):
return {
"is_save_data_on_fail_block_type" : False,
"is_system_block_type" : False
}
def get_fields(self):
return """[{
key: 'name',
type: 'text',
label: 'Name',
hint: "Поле name",
required: true
}, {
key: 'value',
type: 'text',
label: 'Value',
hint: "Поле value",
required: true
}]"""
def get_block_input(self):
return {
"name":'String',
"value":'Long'
}
def get_block_output_options(self):
return {
"default": [
{
"name": "name",
"type": "String"
},
{
"name": "aggr_sum",
"type": "Long"
},
],
}
def get_block_output(self, data_sample:dict):
return self.get_block_output_options()['default']
def get_block_aggr_mode(self, data_sample:dict):
return True
def get_batch_size(self):
return 10
def process_data(self, **data):
block_data = data['block_data']
df = pd.DataFrame(block_data)
return df.groupby('name').sum().reset_index().to_numpy().tolist()
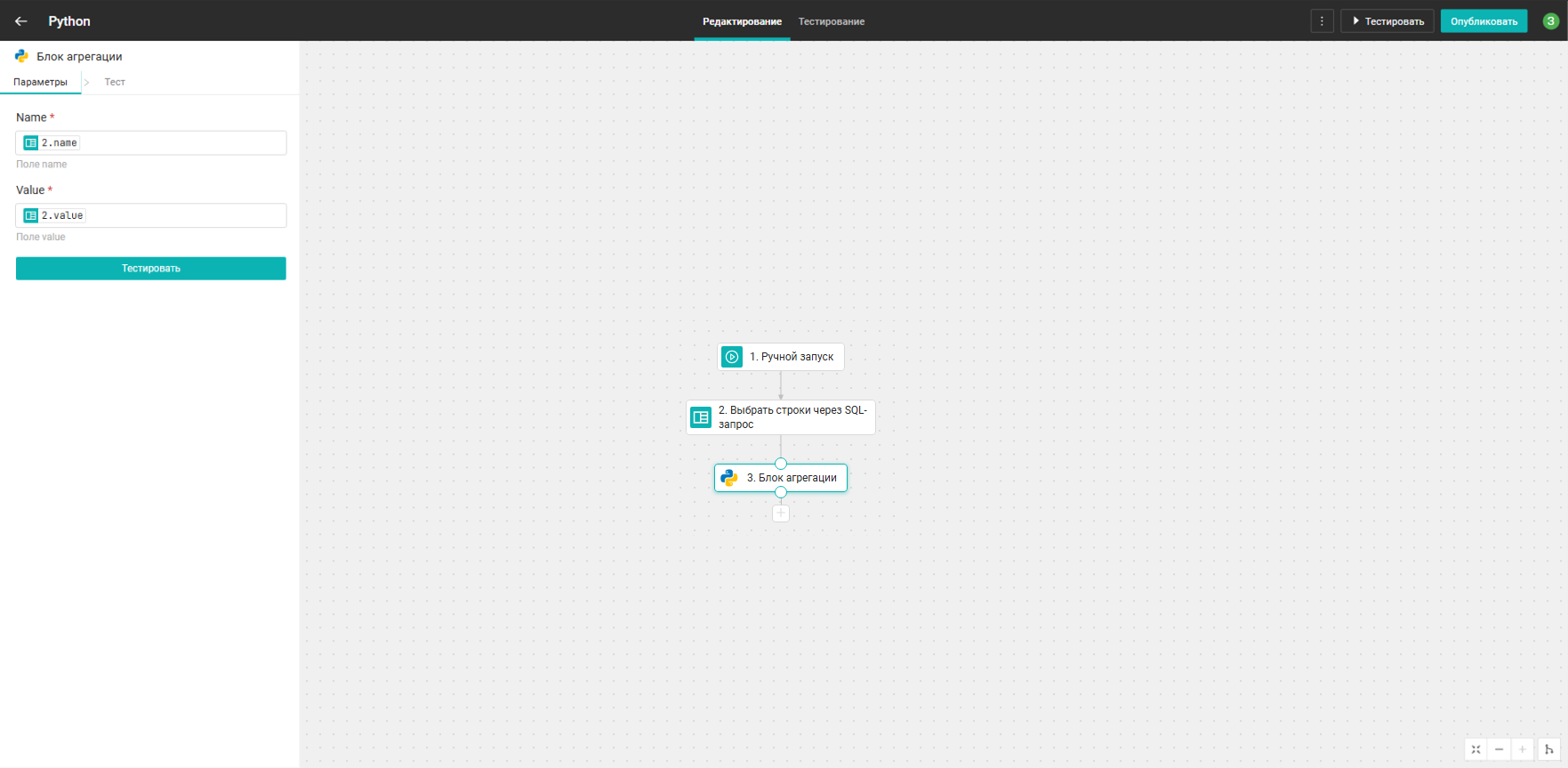
Блок изменения поведения
Блок выполняет операции, например, суммирования или вычитания, над входными данными при изменении положения переключателя в UI (слайдер sw_1).
Структура блока аналогична структуре блока агрегации. За исключением результата методов get_block_aggr_mode и process_data:
get_block_aggr_mode()- Возвращает булево значение False
process_data()— возвращает данные в формате, соответствующемself.block_output- Итеративный режим (глубина вложенности=3):
- 1 уровень - каждый элемент соответствует одной входящей записи
- 2 уровень - каждый элемент соответствует одной исходящей записи. Набор элементов представляет собой ответ на входящую запись
- 3 уровень - каждый элемент соответствует значению поля исходящей записи. Порядок и типы полей соответствуют описанию в
output_variables
- Итеративный режим (глубина вложенности=3):
from sdk.abstract_block import AbstractBlock
class ChangeBehaviourBlock(AbstractBlock):
def __init__(self):
pass
def get_uuid(self):
return "change_beh_block_aba8682c-1040-413b-beb3-12f878e224aa"
def get_type(self):
return "action"
def get_name(self):
return {
"en" : "Testing block info",
"ru" : "Блок изменения поведения",
}
def get_description(self):
return {
"en" : "Testing block description",
"ru" : "Этот блок изменяет структуру выходных данных в зависимости от значения поля `switcher`",
}
def get_compatible_connections(self):
return []
def get_optionals(self):
return {
"is_save_data_on_fail_block_type" : False,
"is_system_block_type" : False
}
def get_fields(self):
return """[{
key: 'num_1',
type: 'number',
label: 'Введи 1 число',
hint: "Поле для ввода первого числа",
required: true
}, {
key: 'num_2',
type: 'number',
label: 'Введи 2 число',
hint: "Поле для ввода второго числа",
required: true
}, {
key: 'sw_1',
type: 'boolean',
label: 'True - сумма, False - разность',
default: true
}]"""
def get_block_input(self):
return {
"num_1":'Long',
"num_2":'Long',
"sw_1":'Boolean',
}
def get_block_output_options(self):
return {
"addition": [
{
"name": "addition",
"type": "Long"
},
],
"subtract":[
{
"name": "subtract",
"type": "Long"
},
]
}
def get_block_output(self, data_sample:dict):
if data_sample['sw_1'] == True: # Пример изменения поведения блока
return self.get_block_output_options()['addition']
else:
return self.get_block_output_options()['subtract']
def get_block_aggr_mode(self, data_sample:dict):
return False
def get_batch_size(self):
return 10
def process_data(self, **data):
block_data = data['block_data']
result = []
for row in block_data:
if row['sw_1'] == True:
result.append([
[
row['num_1']+row['num_2']
]
])
else:
result.append([
[
row['num_1']-row['num_2']
]
])
return result
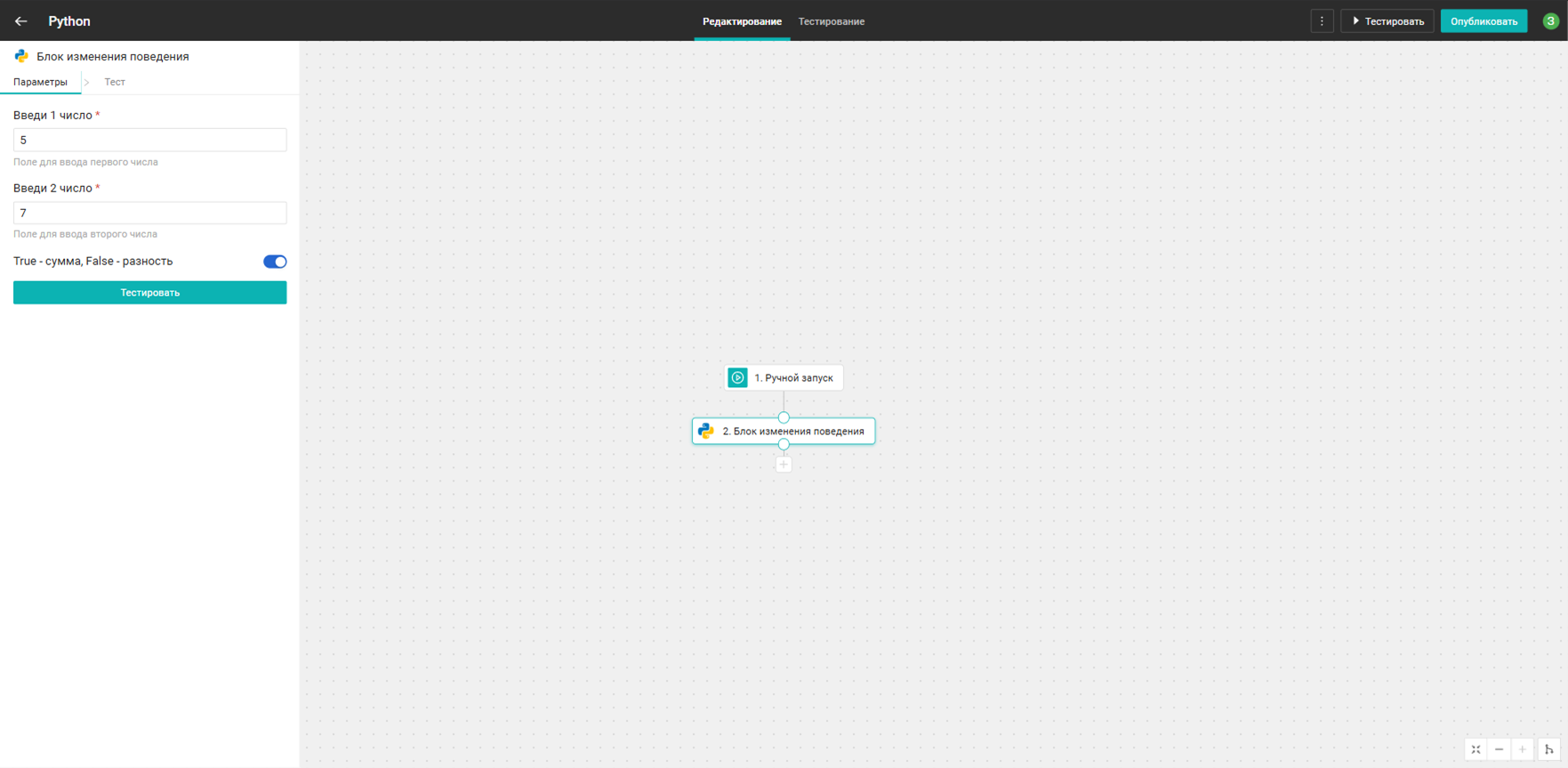
Блок возврата типов
Блок выводит типы входных полей в соответствии с типами данных Python.
Структура блока аналогична структуре блока агрегации. За исключением результата методов get_block_aggr_mode и process_data:
get_block_aggr_mode()- Возвращает булево значение False
process_data()— возвращает данные в формате, соответствующемself.block_output- Итеративный режим (глубина вложенности=3):
- 1 уровень - каждый элемент соответствует одной входящей записи
- 2 уровень - каждый элемент соответствует одной исходящей записи. Набор элементов представляет собой ответ на входящую запись
- 3 уровень - каждый элемент соответствует значению поля исходящей записи. Порядок и типы полей соответствуют описанию в
output_variables
- Итеративный режим (глубина вложенности=3):
from sdk.abstract_block import AbstractBlock
import pandas as pd
class InputTypesEchoBlock(AbstractBlock):
def __init__(self):
self.custom_user_selector = 'multiple'
def get_uuid(self):
return "echo_types_block_2a79bf18-0fa6-4ccd-ac88-af89881937ef"
def get_type(self):
return "action"
def get_name(self):
return {
"en" : "Testing block info",
"ru" : "Блок возврата типов",
}
def get_description(self):
return {
"en" : "Testing block description",
"ru" : "Вернуть типы Python входных полей",
}
def get_compatible_connections(self):
return []
def get_optionals(self):
return {
"is_save_data_on_fail_block_type" : False,
"is_system_block_type" : False
}
def get_fields(self):
return """[{
key: 'str_1',
type: 'text',
label: 'text',
hint: "",
required: true,
enableFullscreen: true
}, {
key: 'str_2',
type: 'text',
label: 'text',
hint: "",
required: true
}, {
key: 'str_3',
type: 'code',
editor: "text",
label: 'text',
hint: "",
required: true
}, {
key: 'str_4',
type: 'code',
editor: "javascript",
label: 'jsArea',
hint: "",
required: true
}, {
key: 'int_1',
type: 'number',
label: 'int_1',
hint: "",
required: true
}, {
key: 'float_1',
type: 'number',
label: 'float_1',
hint: "",
required: true
}, {
key: 'sw_1',
type: 'boolean',
label: 'sw_1',
hint: "bool",
default: true
}, {
key: 'datetime_1',
type: 'text',
label: 'datetime_1',
hint: "ISO дата",
required: true
}]"""
def get_block_input(self):
return {
"str_1":'String',
"str_2":'String',
"str_3":'String',
"str_4":'String',
"int_1":'Long',
"float_1":'Double',
"sw_1":'Boolean',
"datetime_1":'DateTime',
}
def get_block_output_options(self):
return{
"str": [
{
"name": "info_types",
"type": "String"
}
],
"multiple":[
{
"name": "info_types",
"type": "ObjectArray",
"struct": [
{
"name": "key",
"type": "String",
},
{
"name": "value",
"type": "String",
},
{
"name": "type",
"type": "String",
}
]
}
]
}
def get_block_output(self, data_sample:dict):
return self.get_block_output_options()[self.custom_user_selector]
def get_block_aggr_mode(self, data_sample:list):
return False
def get_batch_size(self):
return 10
def process_data(self, **data):
block_data = data['block_data'][0]
if self.custom_user_selector == 'str':
# Variant 1 - single str output
result = []
for key in block_data:
result.append(f'Key: {key}, Value: {block_data[key]}, Python type: {type(block_data[key]).__name__}')
return [
[
[
str(result)
],
]
]
elif self.custom_user_selector == 'multiple':
# Variant 2 - multiple outputs
result = []
for key in block_data:
result.append(
{
"key":str(key),
"value":str(block_data[key]),
"type":str(type(block_data[key]).__name__)
}
)
return [[[result]]]
else:
raise Exception('Unknown custom user selector choice!')
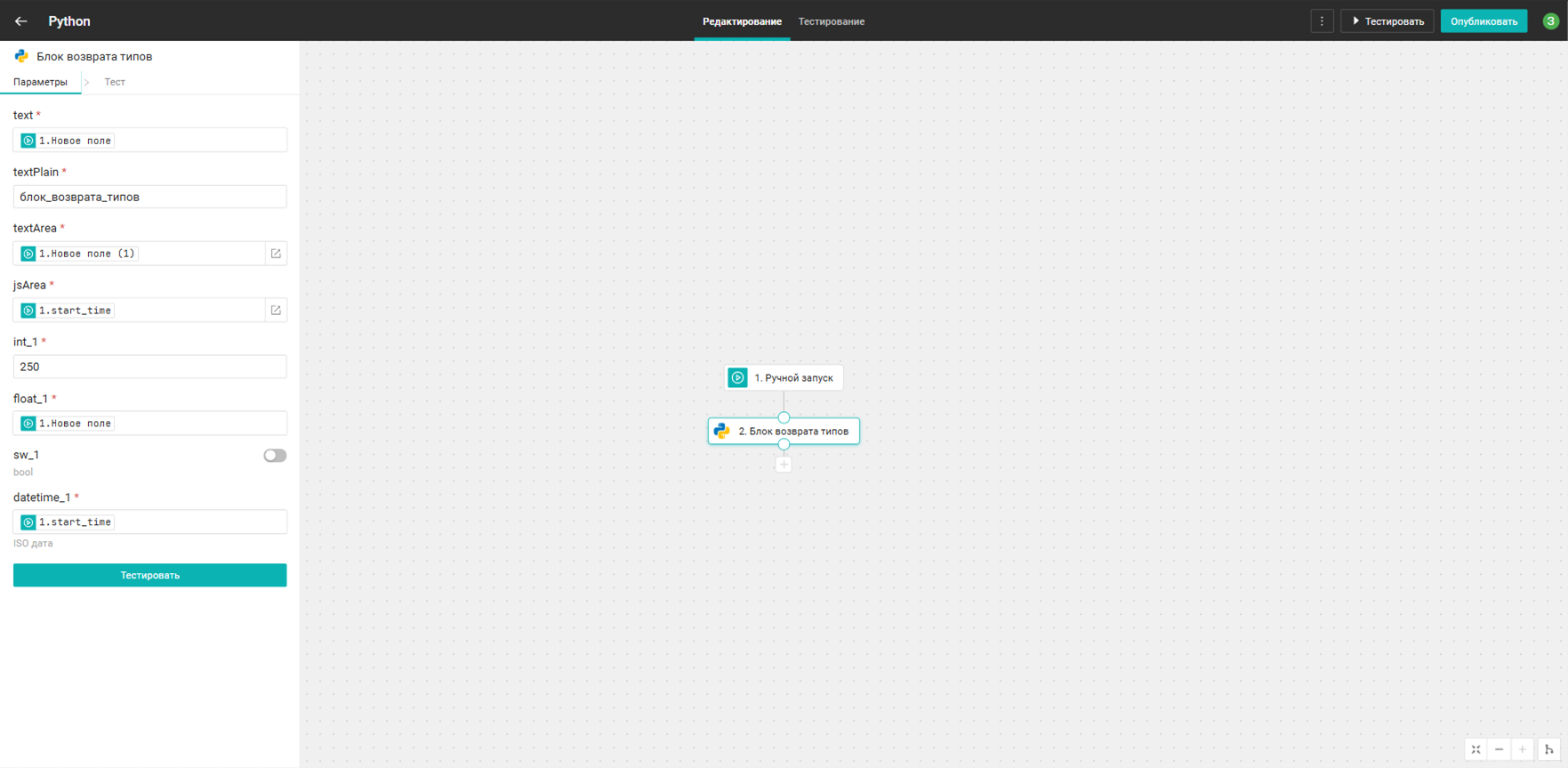
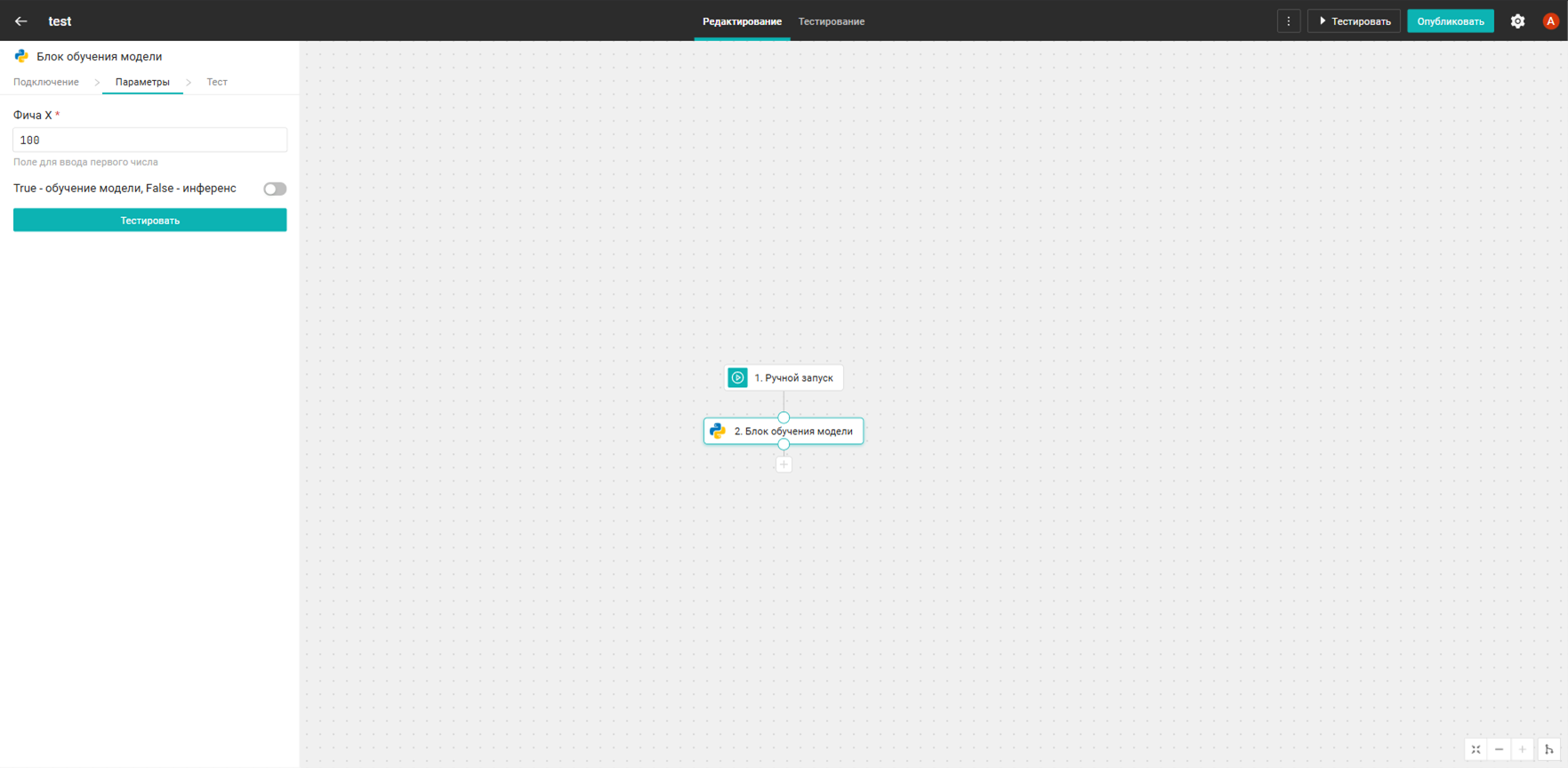
Блок обучения модели
Блок содержит 2 режима:
- Обучение модели для предсказания значений Y в соответствии со значениями X
- Формирование предсказаний значений Y в зависимости от значений X
Режимы переключаются с помощью слайдера sw_1. Модель сохраняется в папку, указанную в переданном подключении.
Структура блока в зависимости от ситуации может быть аналогична структуре блока агрегации или структуре блока изменения поведения.
from sdk.abstract_block import AbstractBlock
from packages.example.connections.vault_connection import VaultConnection
from sklearn.linear_model import LinearRegression
import joblib
import pandas as pd
import os
import pathlib
class DefaultBlock(AbstractBlock):
def __init__(self):
pass
def get_uuid(self):
return "train_block_0cb4b748-6584-4ef2-a849-b56eb620f891"
def get_type(self):
return "action"
def get_name(self):
return {
"en" : "Train model block",
"ru" : "Блок обучения модели",
}
def get_description(self):
return {
"en" : "Train model block description",
"ru" : "Описание блока обучения модели",
}
def get_compatible_connections(self):
return [VaultConnection().get_uuid()]
def get_optionals(self):
return {
"is_save_data_on_fail_block_type" : False,
"is_system_block_type" : False
}
def get_fields(self):
return """[{
key: 'X',
type: 'text',
label: 'Фича X',
hint: "Поле для ввода первого числа",
required: true
}, {
key: 'switch_mode',
type: 'boolean',
label: 'True - обучение модели, False - инференс',
default: true
}, (z, bundle) => {
if (bundle.inputData.switch_mode) {
return [{
key: 'y',
type: 'text',
label: 'Таргет y',
required: false
}];
} else {
return [];
}
}]"""
def get_block_input(self):
return {
"X":'Long',
"y":'Long',
"switch_mode":'Boolean',
}
def get_block_output_options(self):
return {
"train": [
{
"name": "score",
"type": "Double"
}
],
"eval":[
{
"name": "eval_y",
"type": "Long"
},
]
}
def get_block_output(self, data_element:list):
if data_element['switch_mode']:
return self.get_block_output_options()['train']
else:
return self.get_block_output_options()['eval']
def get_block_aggr_mode(self, data_element:list):
if data_element['switch_mode']:
return True
else:
return False
def get_batch_size(self):
return 10
def process_data(self, **data):
connection_data = data['connection_data']
block_data = data['block_data']
vault_path = data['vault_path']
if block_data[0]['switch_mode']:
# Train
df = pd.DataFrame(block_data)
model = LinearRegression().fit(
df['X'].to_numpy().reshape(-1,1),
df['y'].to_numpy().reshape(-1,1)
)
# Check folder
pathlib.Path(os.path.join(vault_path, connection_data['folder_name'])).mkdir(parents=True, exist_ok=True)
joblib.dump(model, os.path.join(vault_path, connection_data['folder_name'], 'model.pkl'))
return [
[
model.score(
df['X'].to_numpy().reshape(-1,1),
df['y'].to_numpy().reshape(-1,1)
)
]
]
else:
model = joblib.load(
os.path.join(
vault_path,
connection_data['folder_name'],
'model.pkl'
)
)
result = model.predict(pd.DataFrame(block_data)['X'].to_numpy().reshape(-1,1)).tolist()
# Eval
return [[[round(r[0])]] for r in result]
Примеры реализаций Python-подключений
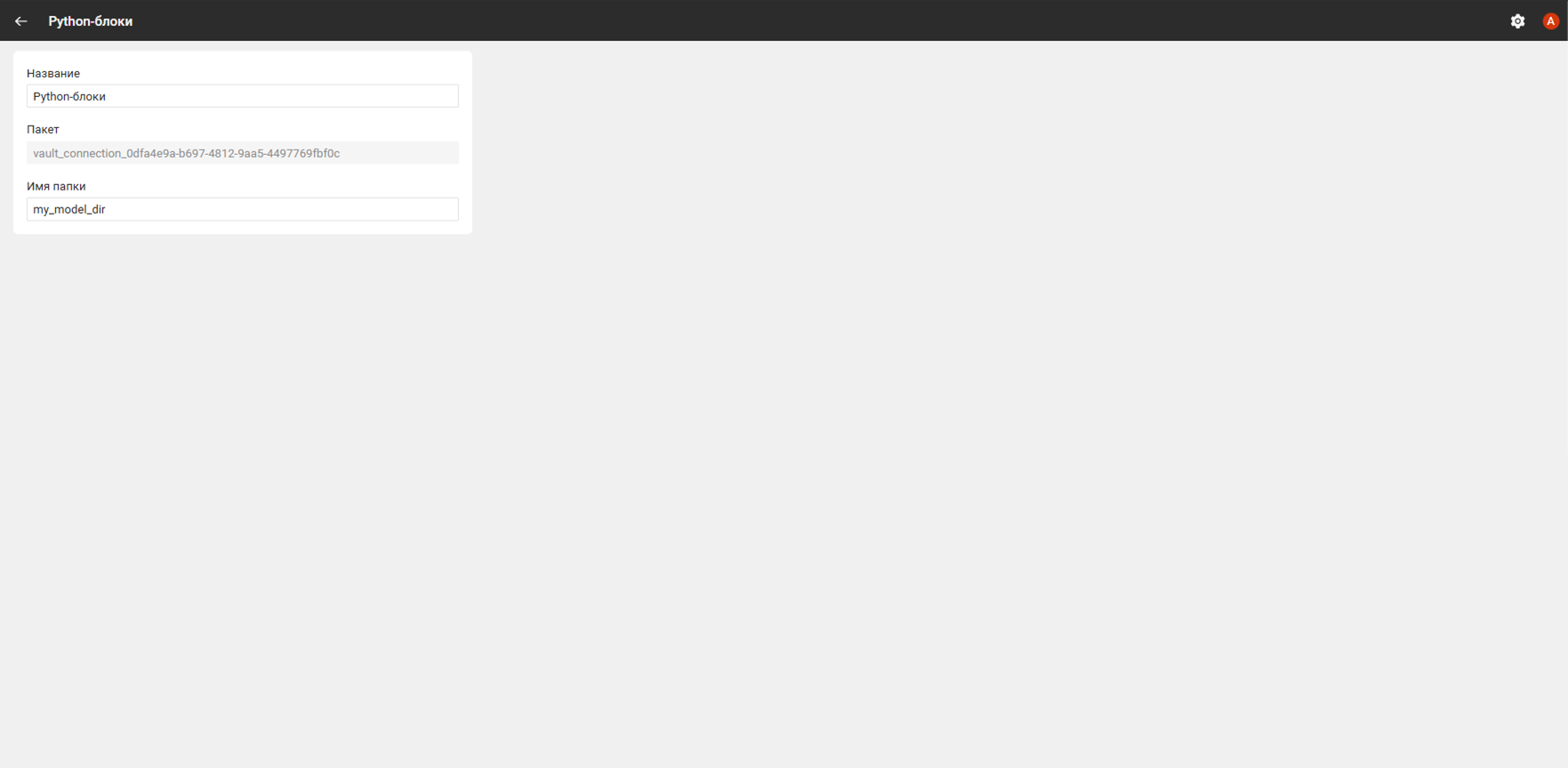
Подключение-хранилище
Блок содержит имя директории в хранилище. Может быть использован для хранения метаинформации между вызовами блока. Например, в блоке обучения модели в директории хранится обучаемая модель.
Структура подключения в примере ниже:
get_uuid()- Возвращает uuid подключения в поле
info_output, имеет форматусловное_имя_подключения_UUID4_хэшдля отличия подключений с одинаковыми условными именами
- Возвращает uuid подключения в поле
get_fields()- Возвращает строковое представление JavaScript описания полей пользовательских интеграций
get_connection_input()- Возвращает поля, которые указаны в значении ключа
fields - Названия типов данных соответствуют типам данных Java
- Возвращает поля, которые указаны в значении ключа
from sdk.abstract_connection import AbstractConnection
class VaultConnection(AbstractConnection):
def __init__(self):
pass
def get_uuid(self):
return "vault_connection_0dfa4e9a-b697-4812-9aa5-4497769fbf0c"
def get_name(self):
return {
"en" : "Vault connection info",
"ru" : "Подключение хранилища",
}
def get_description(self):
return {
"en" : "Testing connection description",
"ru" : "Описание тестового подключения",
}
def get_optionals(self):
return {
"is_category_1" : False,
"option_2" : "category_2"
}
def get_fields(self):
return """[{
"key" : "folder_name",
"type" : "text",
"label" : "Имя папки",
"hint" : "Имя папки для хранения модели",
"required" : true
}]"""
def get_connection_input(self):
return {
"folder_name":'String'
}
Была ли статья полезна?