Функция process
Функция process используется для вычисления агрегированных значений (например, суммы, количества, минимума или максимума) по указанному измерению внутри формул разрезов и мер. Она позволяет выполнять агрегацию по выбранному измерению без необходимости вручную настраивать группировку элементов.
Функция process особенно полезна, когда требуется решить аналитические задачи, связанные с обработкой и использованием агрегированных данных, а именно:
- Получить агрегированное значение для каждого уникального значения колонки разреза
- Использовать результат агрегации в формулах и вычисляемых показателях
- Работать с данными, предварительно сгруппированными по выбранной колонке разреза (измерению)
- Применять определенные условия к агрегированным значениям, а не к отдельным строкам исходных данных
Синтаксис
Функция process вызывается с одним обязательным и одним необязательным параметром: process({агрегирующее выражение}, колонка_разреза)
| Параметр | Описание | Обязательный |
|---|---|---|
{агрегирующее выражение} | Выражение, содержащее агрегатную функцию, колонки, константы или переменные. Определяет, что именно агрегируется. | Да |
колонка разреза | Колонка измерения, по которой выполняется группировка. Если не указана, рассчитывается общая агрегация | Нет |
Особенности функции process:
- Функция поддерживает только одну колонку разреза, использование нескольких колонок разреза одновременно невозможно
- Если колонка разреза не указана, функция вычисляет общее агрегированное значение без группировки
- Не рекомендуется использовать функцию
processвнутри другой функцииprocess, так как это может привести к некорректному результату - Агрегирующее выражение и колонку разреза рекомендуется задавать на основе разных связанных таблиц. Использование колонки разреза из той же таблицы, по которой выполняется агрегация, может привести к дублированию данных и искажению результата
- Функция автоматически оптимизирует вычисления: она учитывает связи между таблицами, выбирает наиболее эффективный путь к данным и объединяет несколько вызовов с одним разрезом в один расчет
- Функция ограниченно учитывает ненаправленные (N:M) связи: они используются для доступа к колонке разреза, но не влияют на расчет агрегированных значений
Примеры использования функции process
В примерах ниже используются две таблицы процесса:
event_log— таблица событий, содержащая:case_id— идентификатор кейсаevent_time— время событияevent_name— название события
case_table— таблица кейсов, содержащая:case_id— ключ кейса, по которому таблица связана сevent_log
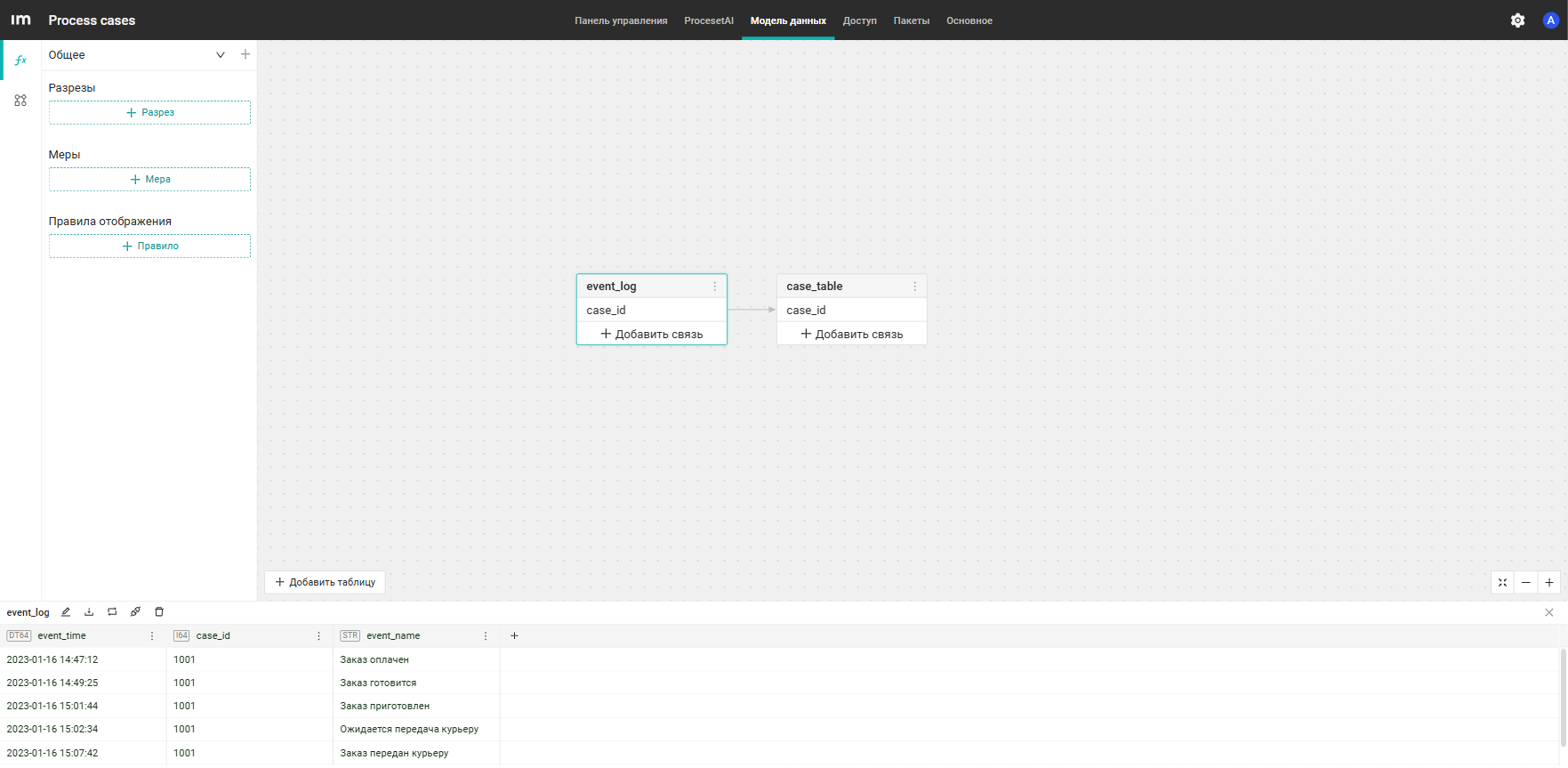
Расчет длительности процесса
Функция вычисляет длительность процесса для каждого case_id. Для этого она находит самое раннее (min()) и самое позднее (max()) время события для каждого экземпляра, после чего вычисляет разницу между этими значениями в секундах с помощью date_diff('second', ...).
process(date_diff('second', min("event_log"."event_time"), max("event_log"."event_time")), "case_table"."case_id")
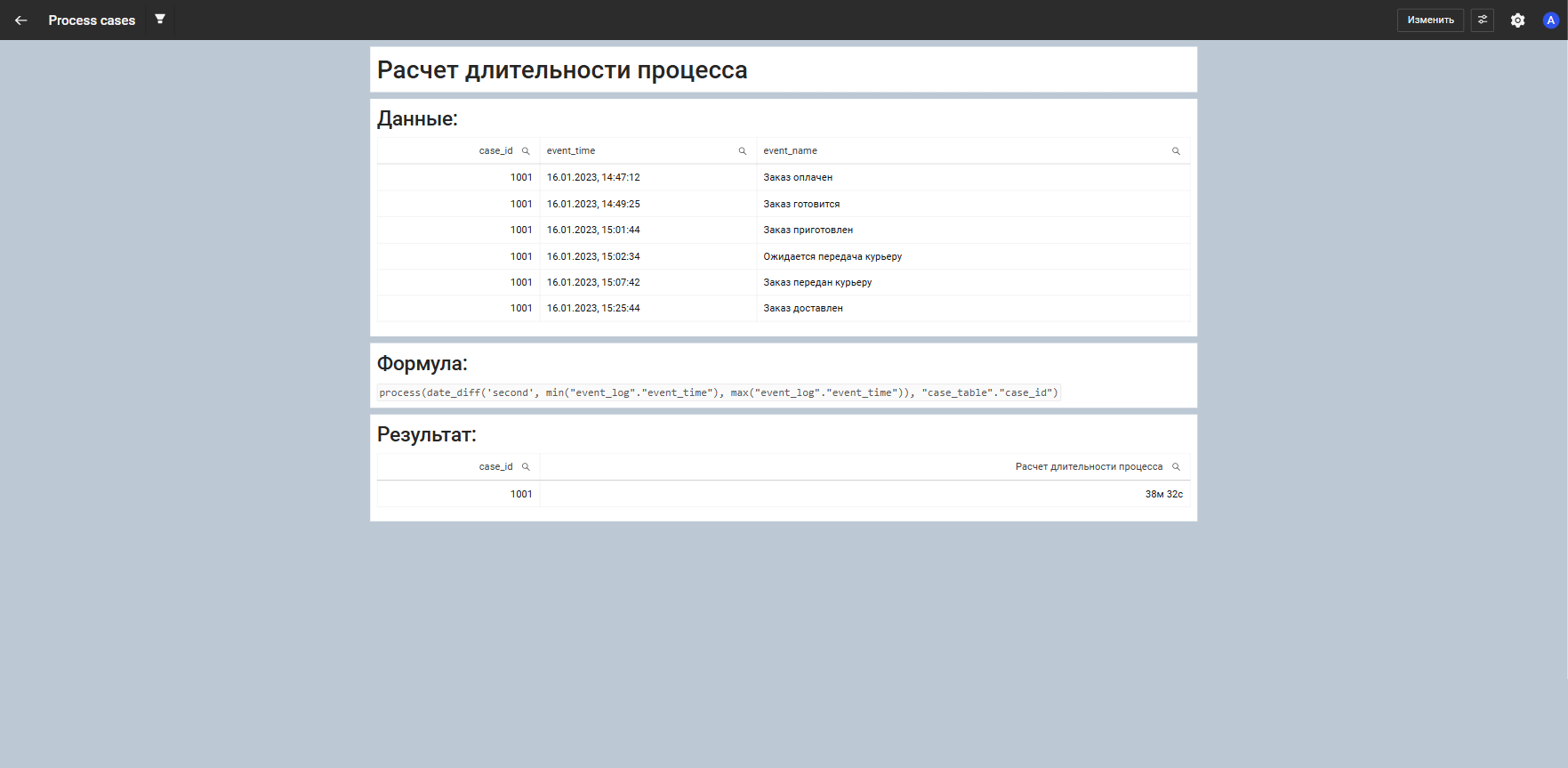
Расчет длительности между этапами
Функция вычисляет, сколько времени прошло между двумя заданными этапами процесса для каждого case_id. Она находит самое раннее время наступления статуса Заказ готовится и самое позднее время статуса Заказ передан курьеру для каждого экземпляра со своим case_id, после чего находит разницу между этими значениями в секундах.
process(if((argMaxIf(toUnixTimestamp("event_log"."event_time"), "event_log"."event_time", "event_log"."event_name" = 'Заказ передан курьеру') - argMinIf(toUnixTimestamp("event_log"."event_time"), "event_log"."event_time", "event_log"."event_name" = 'Заказ готовится') as duration)>0, duration, 0), ("case_table"."case_id"))
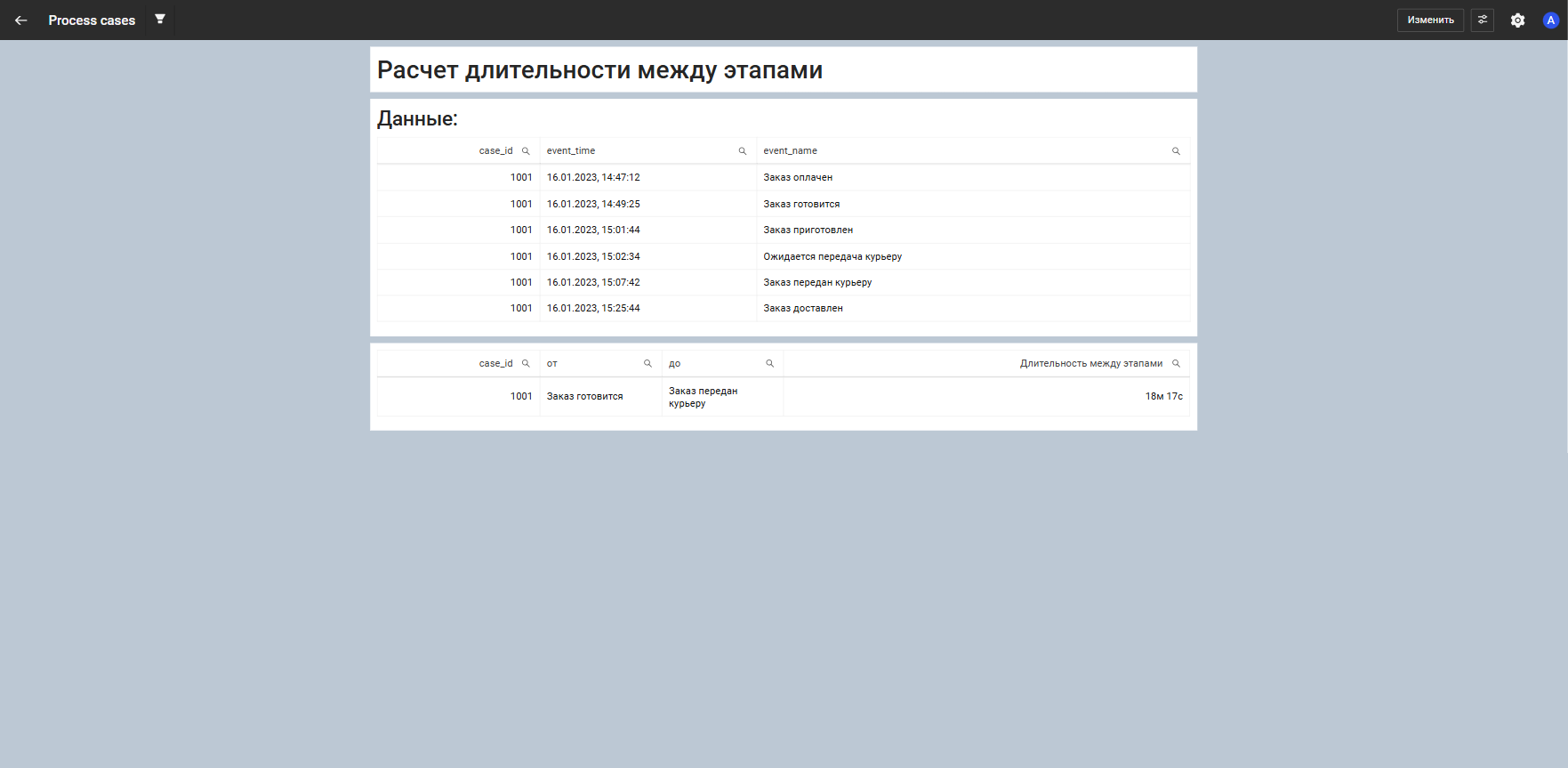
Сценарии протекания процесса
Функция восстанавливает последовательность событий внутри каждого case_id.
Она сортирует статусы по времени и формирует текстовый сценарий, в котором каждый статус выводится на новой строке — в том порядке, в котором он произошел.
process(arrayStringConcat(arraySort((x,y)-> y, groupArray("event_log"."event_name"), groupArray("event_log"."event_time")),'\r\n'),("case_table"."case_id"))
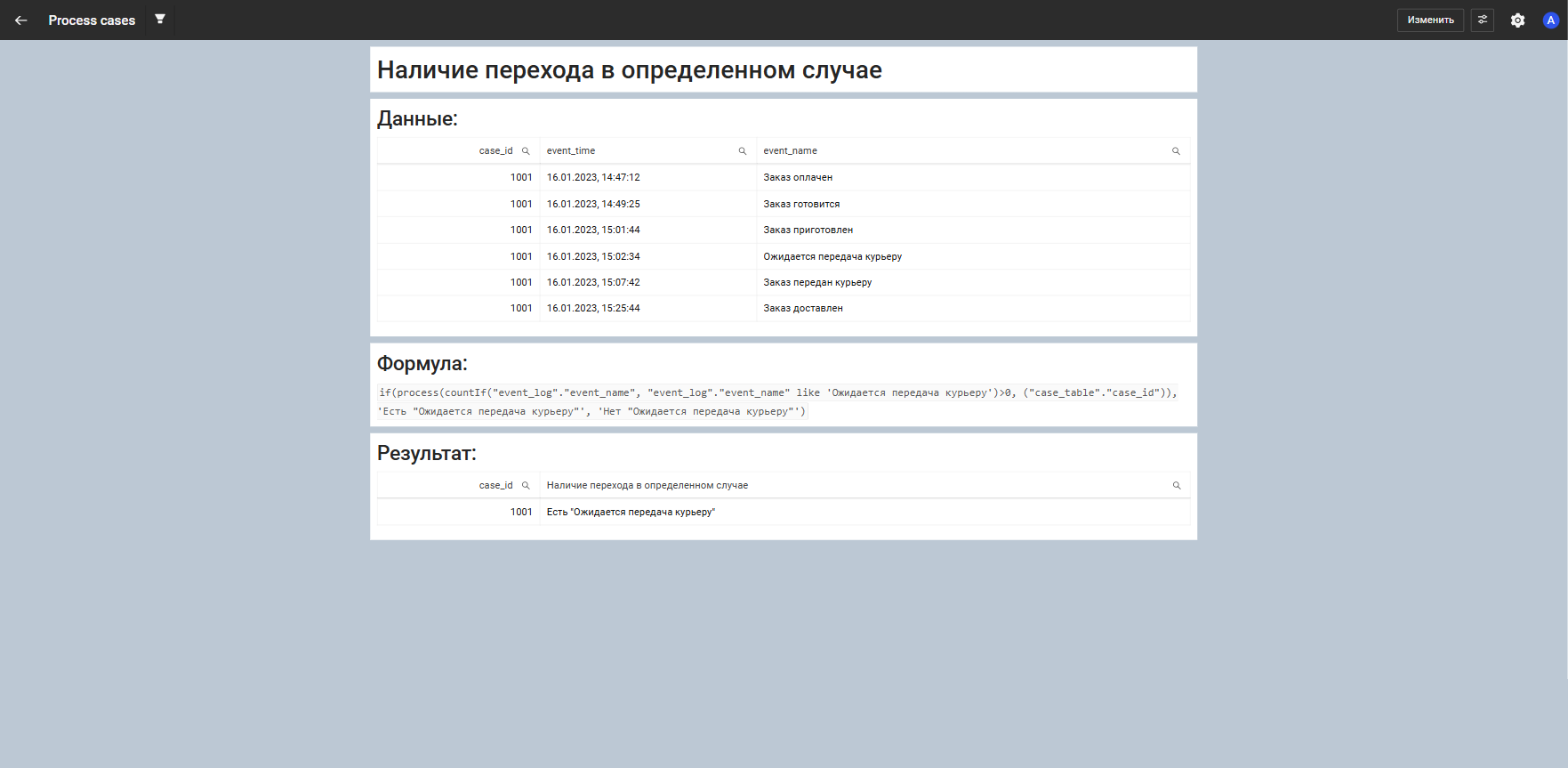
Наличие перехода в определенном случае
Функция определяет, встречается ли у каждого case_id указанный статус.
В примере проверяется, присутствует ли событие Ожидается передача курьеру среди всех статусов кейса хотя бы один раз.
if(process(countIf("event_log"."event_name", "event_log"."event_name" like 'Ожидается передача курьеру')>0, ("case_table"."case_id")), 'Есть "Ожидается передача курьеру"', 'Нет "Ожидается передача курьеру"')
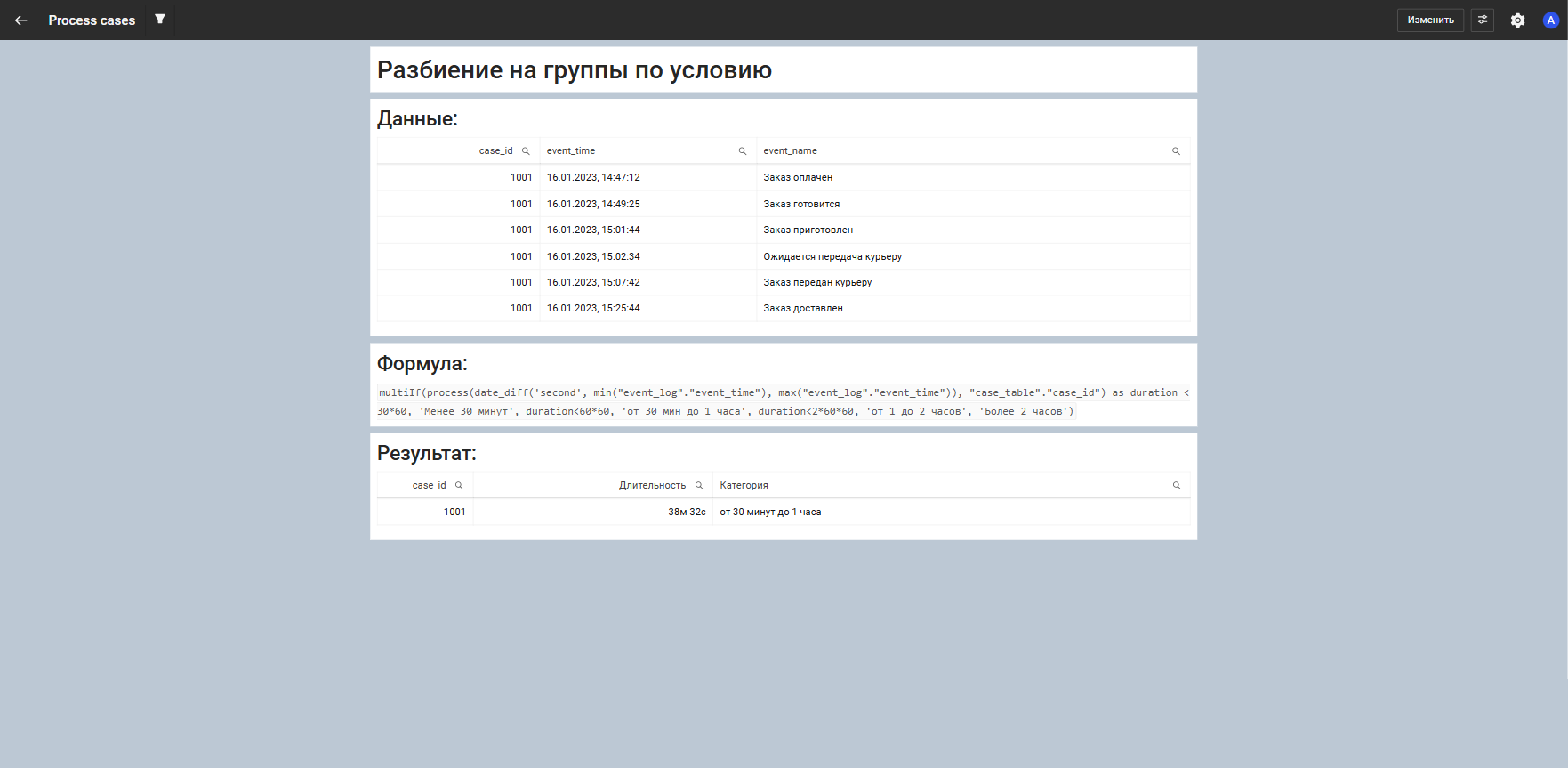
Разбиение на группы по условию
Функция вычисляет длительность процесса для каждого case_id из таблицы event_log и распределяет их по категориям в зависимости от полученного значения. Таким образом, все кейсы распределяются по диапазонам длительности — например, менее 30 минут, от 30 минут до 1 часа и так далее.
multiIf(process(date_diff('second', min("event_log"."event_time"), max("event_log"."event_time")), "case_table"."case_id") as duration < 30*60, 'Менее 30 минут', duration<60*60, 'от 30 мин до 1 часа', duration<2*60*60, 'от 1 до 2 часов', 'Более 2 часов')
Была ли статья полезна?